今年以来,中国市场对 AI 算力的需求并未因海外高端卡受限而降温,反而在应用扩散、模型部署、企业私有化和地方智算建设的多重驱动下持续攀升。与此同时,英伟达算力卡供应的不确定性持续走高,过去被视为“替代方案”的国产AI芯片,正在从政策驱动的备选角色,转向部分客户、部分场景中真正稀缺的主力算力资源。
沐曦万卡集群落地上海临港、摩尔线程夸娥智算万卡集群多城商用、燧原科技云燧系列 GPU 集群进驻成渝智算中心、中国移动呼和浩特国家级液冷智算中心混合部署壁砺与天数智芯…… 一连串落地信号的背后,是国产AI算力芯片行业正式迈过技术验证期,进入规模化落地应用的新阶段。反映到股价上,相关企业的股价也获得了大幅上涨。
智能体时代重构算力消耗逻辑
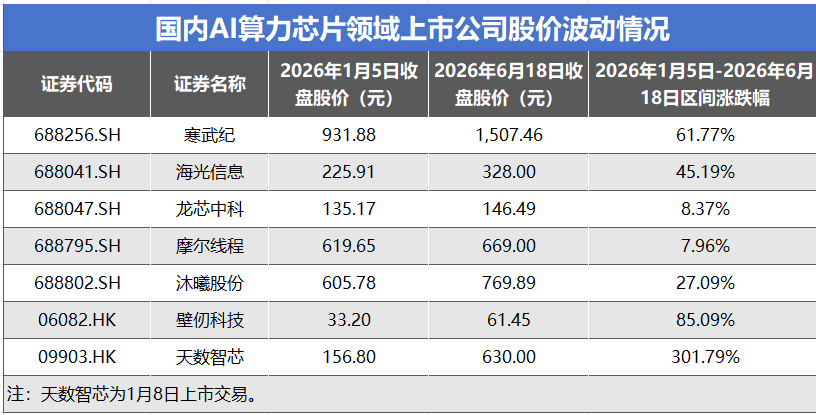
今年以来,国产AI算力芯片板块股价表现亮眼,多家企业涨幅显著,反映出市场对行业基本面改善的强烈预期。其中,寒武纪从年初的931.88元上涨至1507.46元,区间涨幅61.77%,市值稳居AI芯片板块前列。海光信息涨幅45.19%,从225.91元升至328.00元。沐曦股份上涨27.09%,龙芯中科与摩尔线程涨幅相对温和,也分别达到8.37%和7.96%。
港股标的同样涨幅惊人。天数智芯自1月8日上市以来,股价从156.80港元一路攀升至6 月18日的630.00港元,区间涨幅高达301.79%。壁仞科技同期涨幅也达到85.09%,从33.20港元上涨至61.45港元。
股价上涨的驱动因素,除了美国出口管制升级带来的国产替代预期外,更深层的逻辑在于智能体(Agent)时代的到来,正在改变AI算力的消耗方式。过去,AI 更多以网页问答入口的形式存在,用户提问、模型回答,是“一问一答”的单次交互模式。而进入智能体时代,AI开始深度嵌入企业内部流程,进入办公、研发、客服、销售、投研、设计、数据分析等具体业务场景,变成7×24 小时不间断运行的“数字员工”。
业界人士指出,这种变化带来三个重要的改变:一是推理算力需求全面超越训练。 据行业预测,2026年推理算力占比将突破70%,成为AI算力的主导需求。智能体执行复杂任务时,需要持续调用大模型进行推理、规划、决策,token消耗量呈指数级增长。有机构预测,到2026年三季度,智能体类工作负载的token 消耗量将超过传统对话式AI,成为企业算力消耗的第一大来源。
二是企业私有化部署需求激增。涉及核心财务数据、客户资源、研发资料的业务场景,很多企业均选择自建私有算力,部署垂直大模型与智能体应用。对于数据安全和自主可控有更高要求的政企客户,国产芯片成为首选。
三是算力需求从集中式走向分布式。智能体往往需要多模型协作、多步骤推理,对算力的需求不再是“超大集群集中训练”,而是“海量节点分布式推理”。这种需求结构与国产芯片的供给特点更加匹配。单卡性能虽与海外旗舰有差距,但在海量推理场景下,凭借性价比、供应稳定和本地化服务优势,国产芯片的竞争力正在快速凸显。
需求井喷国产AI芯片业绩高增
从市场应用角度来看,多个国产算力集群正在落地,从千卡示范到万卡商用。例如,华为昇腾在深圳、合肥等地建成多个万卡级智算中心;中科曙光郑州 3 万卡国产算力池正式上线运营,兼容多品牌国产加速卡;中国移动呼和浩特万卡液冷智算中心规模部署壁仞、天数智芯产品等。
市场需求的快速增长,也直接反映在相关企业的财报成绩单上。寒武纪一季度实现营业收入28.85亿元,同比大幅增长 159.56%,创下历史单季新高;归母净利润达10.13亿元,同比增长185.04%。公司产品持续在运营商、金融、互联网等重点行业落地,并已规模应用于大模型算法企业、服务器厂商,辐射云计算、能源等多个领域。
海光信息延续稳健高增态势,一季度营收达40.34亿元,同比增长68.06%;归母净利润8.77 亿元,同比增长22.90%,“CPU+DCU”双轮驱动战略成效显著。摩尔线程一季度实现营收7.38 亿元,同比增长155.35%,更重要的是实现了上市以来的首次单季盈利,归母净利润2936万元,标志着国产通用 GPU 商业化进程迎来关键拐点。
沐曦股份一季度营收5.62 亿元,同比增长75.37%;归母净利润亏损9884万元,同比大幅减亏57.49%,随着曦云C550等新品切入高端训练场景,盈利改善趋势明确。龙芯中科一季度营收 1.35 亿元,同比增长 7.96%,亏损同比收窄 24.66%,在CPU+AI 加速卡全栈自主路线上稳步推进。
未来趋势:生态自主化与商业兑现
展望未来发展,国产AI算力芯片行业将沿着两条主线展开:一是生态建设从兼容CUDA走向自主全栈;二是商业化从研发烧钱转向订单兑现与资本化提速。
软件生态曾是国产芯片最大的短板。长期以来,全球95%以上的AI开发者依赖英伟达CUDA 生态,国产芯片只能通过兼容层实现代码迁移,始终处于跟随者地位。2026 年,这一局面正在发生变化。目前主流国产GPU均推出了成熟的CUDA兼容工具链,开发者无需大规模改写代码即可迁移大模型。与此同时,产业链联合共建统一软件底座的趋势日益明显。芯片厂商、服务器厂商、云厂商、算法企业联合搭建统一编译框架、跨芯片调度中间件,打破单一厂商封闭生态。昇腾、昆仑芯、海光光合组织等生态平台各自聚集了数千家合作伙伴,算子库、开发社区、行业模型套件日趋完善,"有芯片无开发者" 的困境正在成为历史。
更具标志性意义的是,国产AI算力芯片行业正在走出“研发烧钱”的阶段,进入商业化兑现的周期。寒武纪实现连续盈利,经营活动现金流首次季度转正,开始摆脱依靠融资"的状态。摩尔线程成为首家实现季度盈利的国产通用GPU上市公司。沐曦、壁仞、燧原等企业亏损持续收窄,订单规模化落地带来的营收增长,正在逐步覆盖高强度的研发投入。
与此同时,国产芯片企业也在拓展多元化商业模式, 不再只销售硬件加速卡,而是衍生出整机服务器、算力租赁、私有化集群交付、MaaS 模型服务、算力运营等。地方智算中心普遍采用“芯片+机房+运维”打包采购模式,大幅提升了厂商的整体营收规模。从卖芯片到卖算力、从卖产品到卖服务,商业模式的升级正在为行业打开更大的成长空间。