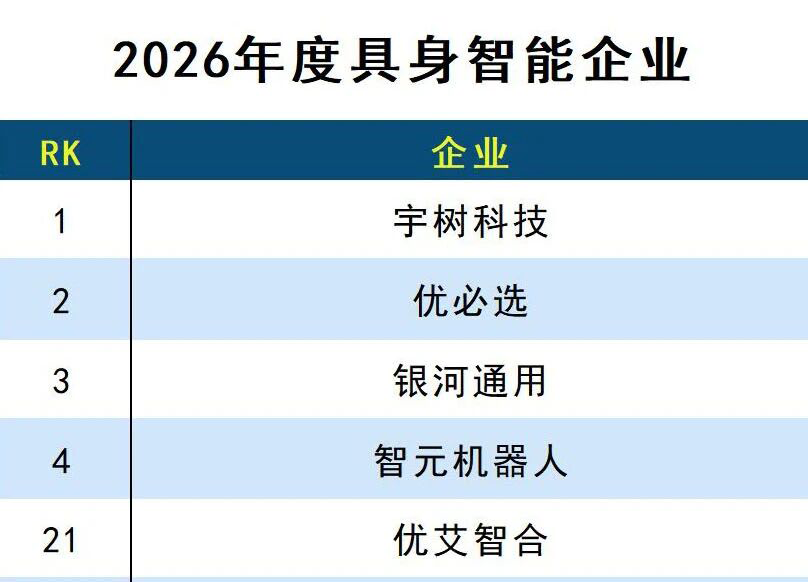
2026年人工智能将加速从数字空间走向物理世界,具身智能是这一进程的关键技术之一。目前的具身智能行业正处于从实验室走向产业化应用的关键阶段,异构芯片、VLA模型,以及软硬件的协同创新,成为推动行业爆发式增长的重要引擎。日前集微网采访了英特尔研究院副总裁、英特尔中国研究院院长宋继强,深度解读具身智能的技术突破与产业未来。
异构计算:具身智能芯片的核心共识
在具身智能技术的发展进程中,芯片的作用十分关键,它是连接数字智能与物理执行的核心硬件载体,直接决定了设备的响应速度、控制精度与落地可行性等。对于具身智能相关芯片的技术发展趋势,宋继强指出,异构计算已经成为此类芯片产品发展的共识,CPU+GPU+NPU 的异构组合是当前的主流技术方向。
这是因为单一架构无法满足“感知—决策—执行”闭环中对高通量、低延迟、高精度、低功耗的多元需求,具身智能的技术特性决定了其芯片必须采用异构架构,而非单一架构的“全能方案”。VLM/LLM等大模型的核心需求是高通量数据处理,如视觉输入、语言推理,以支撑复杂模型的持续运行。此时,GPU就是一个好的选择,例如英特尔酷睿Ultra芯片中的Xe核心,能以高能效比承载大模型运算。
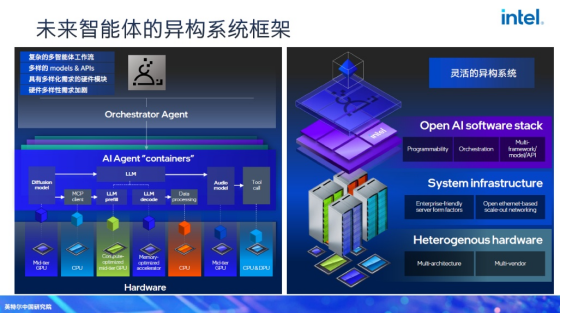
在Action Expert(任务映射与指令生成)系统中,核心需求是低延迟、低功耗与高实时性,此时NPU更加适配,能以低功耗快速完成“任务规划到执行指令”的映射,满足动作生成的实时性要求。而MPC控制的核心需求是超高实时响应与高精度浮点运算。CPU是更加适合的载体。
基于异构理念,英特尔推出了针对性产品与技术方案,包括第三代酷睿 Ultra For Edge 处理器、全栈软件生态支撑等。宋继强进一步提出,具身智能的异构计算不应局限于单芯片或单终端,而应是“终端+边缘+云”的跨网络资源池。终端机器人搭载异构芯片满足实时性需求,边缘服务器提供额外算力支撑大模型推理,云平台负责大规模训练与数据存储。这种架构既避免了终端算力冗余导致的成本高企,又通过低时延通信保障了整体响应速度,尤其适合工业场景中“多机器人协同”的需求。
针对“未来是否需要机器人专用芯片”“何时推出”等问题,宋继强也发表了观点。其认为,当前并非推出专用芯片的最佳时机,只有当具身智能机器人的量产规模足够大(如百万台级别),专用芯片的研发成本才能通过规模效应摊薄,商业上具备盈利可行性;当前行业仍以试点、原型机为主,规模不足支撑专用芯片的投入。
此外,当前业界对VLA、世界模型等技术路径的选择尚未统一,机器人本体如自由度、执行器类型也没有公认的标准,缺乏明确的系统级规格,专用芯片设计尚无从谈起。然而,一旦系统级规格确定,开发出相关的芯片产品并非难题。
VLA:尚需进一步解决精度与幻觉问题
VLA(视觉—语言—动作模型)是当前具身智能领域的技术范式,其核心价值在于打破视觉感知、语言理解与动作执行的技术壁垒,将三者统一到完整的决策闭环中,让具身智能设备实现“看懂场景、理解指令、精准行动”的端到端能力。针对 VLA 的未来发展,宋继强指出,VLA当前已实现“能做什么”的技术验证,未来的核心方向是突破“做得好、成本低、能落地”的产业瓶颈,其发展逻辑将围绕实用性展开。
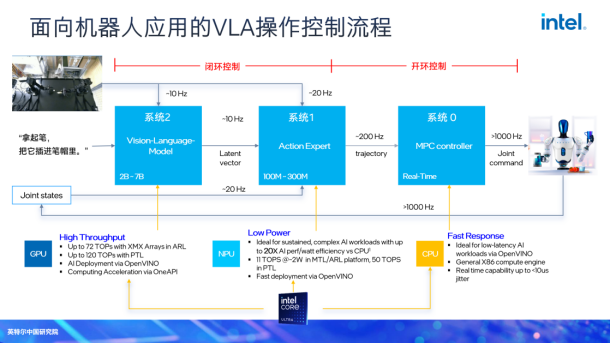
宋继强指出,目前VLA在训练测试环境里能给出可以过关的序列,但从精度以及不出幻觉的角度还无法保证。比如测试大量任务后,准确度可达60%到70%。精度取决于Action Expert能训练到多高精度,以及能输出多高频率的数据。从这一点来看,VLA的泛化能力仍然受限。第二,VLA的Action Expert本身与机器人本体挂钩,所以切换本体时,后面仍有较大调优代价,一致性也不一定能保证得很好。第三是幻觉问题。幻觉大模型自己解决不了,因为它并没有真正理解“这个场景到底是什么”。这也是为什么现在要用世界模型来补充。世界模型的作用就是补充场景里物体之间的真实关系、物理定律与规则。另外,VLA主要基于视觉,训练代价仍然很大。所以目前来看,VLA更适合支持短程任务,而不能支持长程,长程任务就需要切开。
软硬件解耦的核心价值与落地限制
软硬件解耦已成为智能驾驶、智能制造设备等领域的核心发展方向,通过分离硬件载体与软件功能,既能降低软件开发与迭代成本,避免硬件更换带来的全流程适配难题,又能提升系统灵活性,让上层智能算法在不同硬件平台上高效复用,加速技术落地与场景拓展。这一思路同样引发了具身智能领域的讨论:人形机器人等设备是否需要遵循软硬件解耦逻辑?解耦的边界又该如何界定?
对此,宋继强强调,具身智能领域同样追求软硬件解耦,且解耦的核心价值与其他行业一致:一是降低开发与适配成本:工业级具身智能设备对可靠性、稳定性要求极高,若软硬件深度绑定,更换硬件时需重新进行全流程测试与适配,开发成本会大幅增加。二是提升系统灵活性:解耦后,上层智能算法可摆脱硬件限制,在不同形态的具身设备间复用,无需针对单一硬件重复开发。
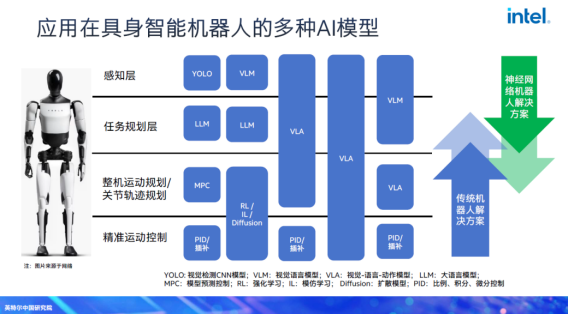
但与智能驾驶、通用计算设备不同的是,因为与物理世界有强交互性,具身智能设备又存在天然难以完全解耦的部分。以VLA为例,典型VLA分为两层:前面VLM负责去“看”场景和接收语言输入,产生一段用语言类token表示的动作序列,比如“我要去喝水”,它会产出若干动作序列,但这套序列并不会直接映射到关节控制参数,让机器人的关节动起来。解耦发生在语义级执行序列产生之后,即如何对应到具体本体的动作,是可以解耦的,而且这种解耦非常重要。否则今天换成A家双臂机器人,明天换成B家单臂机器人,切换代价会很大。也就是说,上层感知与规划可以相对独立出来的,复用于不同机器人。
但从拿到规划任务要求到生成具体机器人控制指令,比如轮臂式机器人要控制轮子电机、胳膊电机、灵巧手等,不同机器人的自由度也不同,这就无法解耦,因为它与各家本体是强相关的。即与机器人本体强绑定的执行控制环节,这部分无法实现通用化解耦。