
近日,同济大学软件学院赵生捷教授团队联合上海人工智能实验室(上海AI Lab)、上海交通大学、北京大学及商汤科技发布首个大模型因果推理开放评测体系及开放平台CaLM(Causal Evaluation of Language Models)。首次从因果推理角度提出评估框架,为AI研究者打造可靠评测工具,从而为推进大模型认知能力向人类水平看齐提供指标参考。

因果推理是人类认知能力最重要的特征之一,提升因果推理能力被视为由机器智能迈向人类智能水平的关键步骤。为对大模型进行科学有效的因果推理能力评估,赵生捷教授联合团队在CaLM中提出包含因果评估目标(Causal Target)、评估方式(Adaptation)、评估标准(Metric)及错误分析(Error)的评估框架,同时构建了超过12万道题目的中英文数据集。基于CaLM,联合团队首次对28个当前主流大模型进行了因果推理能力评测,共产生了50项实证性发现。
CaLM采用了一套灵活、易扩展的评估框架,并按照预设实施顺序进行评测:因果评估目标(Causal Target)→评估方式(Adaptation)→评估标准(Metric)→错误分析(Error)。CaLM的评估框架设计与实施流程,还可应用于数学推理、专业知识及长文本处理等模型能力评估体系构建。
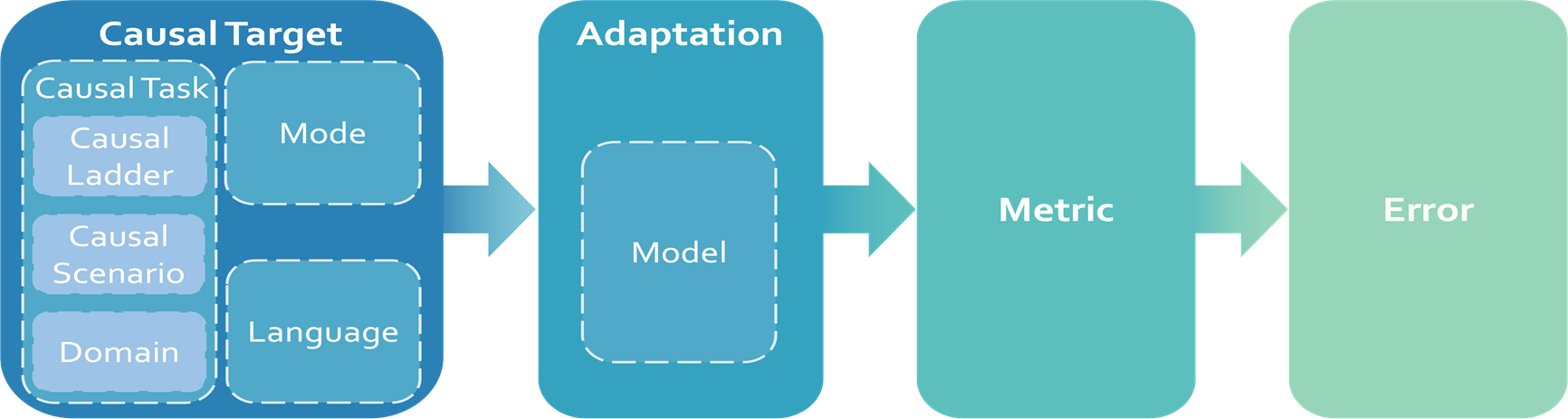
CaLM评估框架
在当前普遍采用的Judea Pearl提出的因果阶梯理论基础上,CaLM进一步发展并明确了四个层次的因果任务:因果发现(Causal Discovery)、关联(Association)、干预(Intervention)及反事实(Counterfactuals)。每层次任务按复杂程度进行基础到高级的顺序排列,构成了自下而上的框架。
因果发现旨在从数据或语义中推测出潜在的因果结构,关联探索数据间的统计依赖关系,干预预测有意改变环境中的变量所带来的影响,以及反事实则对假设的替代场景进行推理。针对四个任务层次,CaLM设计了因果归因、解释移除效应、对撞偏差和反事实推理等21种因果场景,覆盖COPA、CLADDER及CaLM-IV等多种数据集和问题类型。
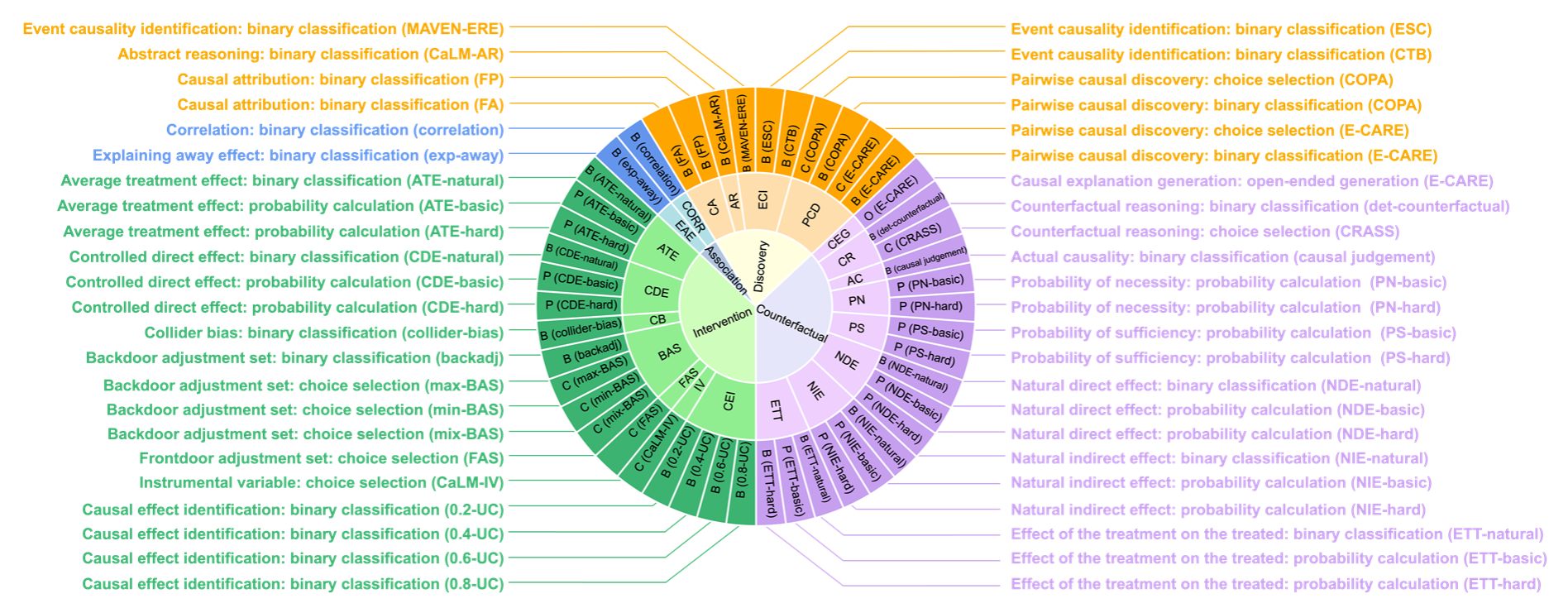
CaLM因果评估目标设置
在评估方式的选择上,CaLM采用基准提示、对抗性提示、思维链及上下文学习等9种评估方式。综合考量了评测实践过程的受众广泛性、用户易用性以及实验控制性。针对模型、提示词以及因果场景,CaLM中分别设置了不同的评估标准,覆盖包括准确率、鲁棒性、理解度等7种,全面反映模型的因果推理能力和鲁棒性、提示词有效性。越复杂的因果场景模型越难解决,从而该场景成熟度越低,因此CaLM同时设置了考察因果场景成熟度的评估标准。
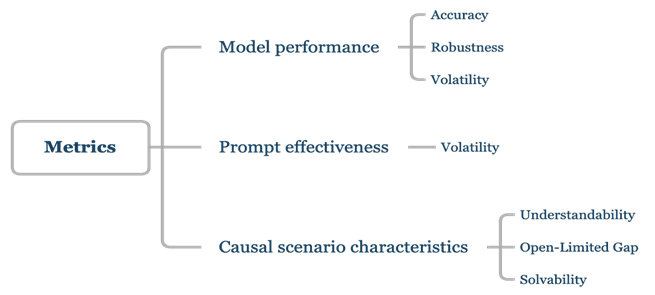
CaLM评估标准
联合团队认为,大模型评测中产生的错误,是应用于下一阶段研究的宝贵资源。通过发现并定义错误,研究人员能够更清晰地界定模型能力边界,识别模型存在的缺陷,并寻找对应提升路径。为此,CaLM在评估过程中,将模型产生的错误系统地分为两大类:定量错误(Quantitative)和定性错误(Qualitative)。不仅对每类错误进行明确的定义,还对所有定量错误都进行了统计分析,以量化错误的频率和模式。CaLM也对于所有定性错误进行了深入的案例研究,以理解错误的具体情况和成因。
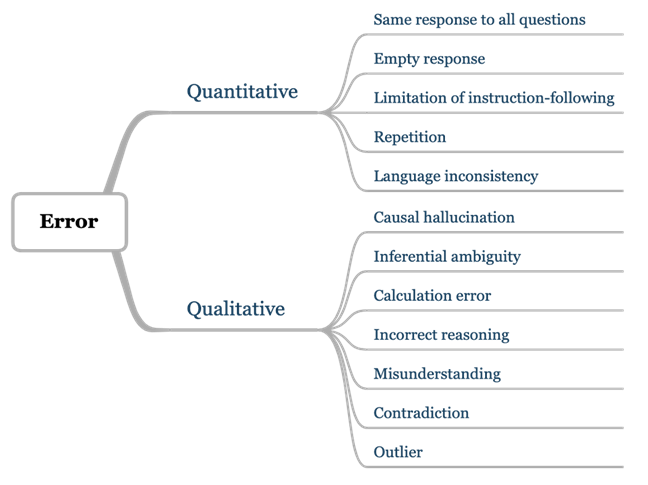
CaLM错误结果分析框架
为了使因果推理能力评估有“考题”可循,联合团队构建了一套全新的评测数据集。基于四个层级的因果任务设置,涵盖了丰富的因果概念,包含超过12万条中英文数据。同时,研究人员还细致地将文本模态划分为日常表达(Natural)、抽象表达(Symbolic)和数学表达(Mathematical)三种子态,以考察模型在不同类型模态下的理解能力。该数据集90%的内容为全新构建,10%来自于现有公开数据集,既能与已有公开结果进行对比,反映评估的有效性,又能避免训练集数据污染问题。
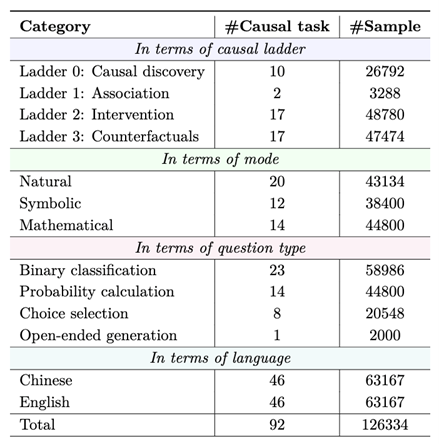
CaLM数据集问题类型统计概览
针对28个当前主流大模型,联合团队使用了CaLM进行因果推理能力评测,共产生了50项实证性发现。评估数据和可视化结果均已发布至CaLM项目主页。(https://opencausalab.github.io/CaLM/),同时CaLM数据集、评估流程和错误分析的全流程均已开源(https://github.com/OpenCausaLab/CaLM),便于产学界自主研究使用。
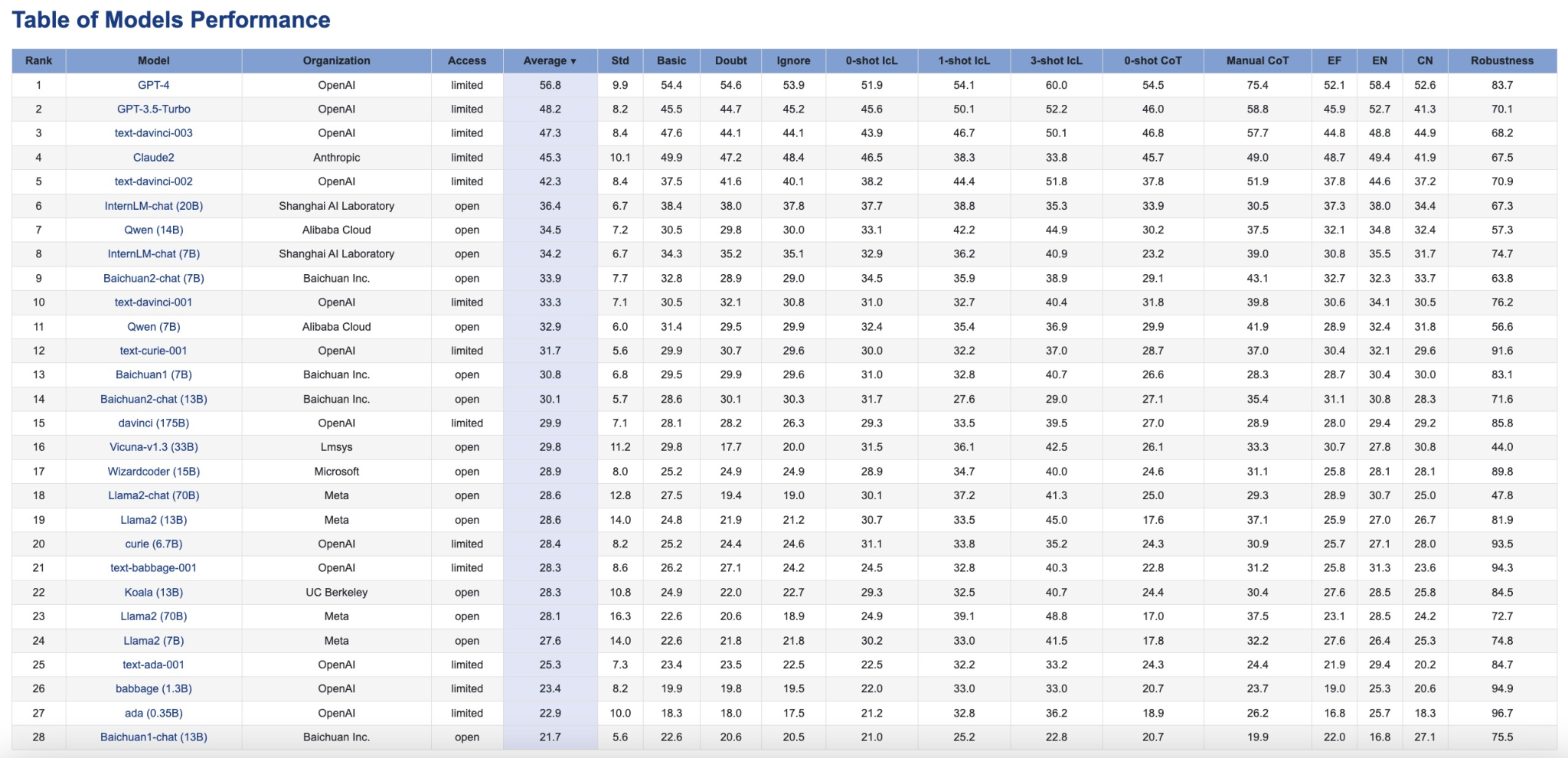
CaLM评估结果








