
Common Voice 是一项旨在通过众包的方式,来教授机器人如何像真人般讲话的项目。Mozilla 基金会在几年前发起的该项目,现已迎来与芯片巨头英伟达的最新合作。其旨在允许志愿者为世界上最大的开放式通用语音数据集贡献一份力,从而推动语音合成与识别技术的发展。

(来自:Mozilla)
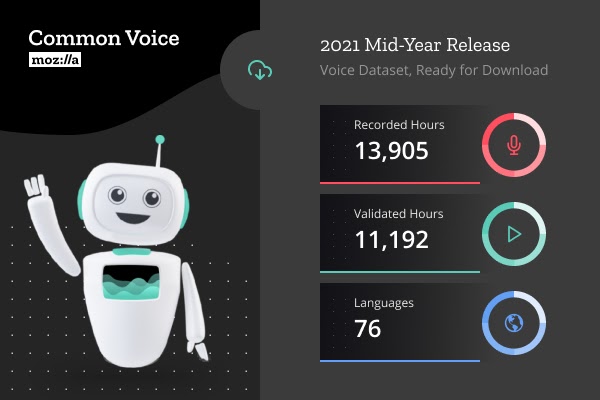
随着新版公共语音数据集的发布,可知 Common Voice 语料库已拥有超过 13000 小时的众包语音数据。
与上一版相比,其新增了 4622 小时的内容,并且迎来了对 16 种语言的支持,包括:巴萨语、斯洛伐克语、北库尔德语、保加利亚语、哈萨克语、巴什基尔语、加利西亚语、维吾尔语、亚美尼亚语、白俄罗斯语、乌尔都语、瓜拉尼语、塞尔维亚语、乌兹别克语、阿塞拜疆语、以及豪萨语。
目前 Common Voice 已经收集了 76 种语言的公共语音数据库,以及超过 18.2 万份独特的声音,贡献者社区在过去六个月内迎来了 25% 的增长。
(传送门:NVIDIA)
语音时长 13905 小时,较上一版本增加了 4622 小时。排名前五的语言分别为英语(2630 小时)、基尼亚卢旺达语(2260 小时)、德语(1040 小时)、加泰罗尼亚语(920 小时)、以及世界语(840 小时)。
增长百分比最高的是泰语(从 12 小时到 250 小时、增长近 20 倍),卢干达语(从 8 小时到 80 小时、增长 9 倍),世界语(从 100 小时到 840 小时、增长超 7 倍),泰米尔语(从 24 小时到 220 小时、增长超 8 倍)。
感兴趣的朋友,可移步至 Common Voice 官网(传送门),为这个公共语音数据集贡献自己的一份力量。或者前往 GitHub 存储库,获取特定的元数据集和使用说明。
最后,作为 Mozilla 与 NVIDIA 的一个合作项目,相关训练模型也可通过 Nvidia NeMo 免费获得,后者是该公司打造的用于构建语音识别和对话模型的工具包。







