
6月14日至6月18日,超大规模集成电路研讨会(Symposium on VLSI Technology and Circuits,简称VLSI)在美国夏威夷成功举办。本次大会,学院部分师生参会展示成果,并在会上与各国顶尖学者进行了充分的交流。此外, 在VLSI2026全体大会上,举行了VLSI2025最佳学生论文颁奖仪式,北京大学的 “First Demonstration of 1T FDSOI-based >1000fps Image Sensor with In-pixel Computing”是唯一获奖论文。这是VLSI大会自1981年创办45年以来,中国大陆的首个最佳论文奖。集成电路学院博士研究生唐楠与于贵海为该论文的共同第一作者,周正助理研究员与黄鹏研究员为共同通讯作者。
在本届VLSI大会上,北京大学集成电路学院/集成电路高精尖创新中心有4篇高水平论文入选,向国际同行展示了相关方向的最新研究成果。上述4篇论文内容涉及先进存储器件技术、先进功率器件技术、AI加速芯片技术、神经探针芯片技术等。论文的详细内容如下:
一、高速度高耐久性的三维铁电晶体管存储阵列
生成式人工智能中,大模型KV cache等高频访问“温数据”对存储器提出了更高要求。三维垂直铁电场效应晶体管(3D FeFET)有望利用1T结构、三维堆叠集成和铁电材料的非易失特性,为下一代高密度存储提供低成本、高速、高能效方案。然而,3D FeFET仍面临耐久性不足、写入速度受限以及阵列扰动等关键挑战。
针对上述问题,北京大学唐克超研究员-黄如教授团队联合长江存储,提出并展示了一种综合性能全面优化的三维垂直AND型FeFET阵列,实现了>1012次超高写入耐久、±2 V/20 ns高速写入、无延迟写后读取、0.001 μm²沟道面积,以及4Kb规模阵列无错误读出验证。该器件采用超晶格铁电层与氧空位调控的IGO沟道协同优化,同步提升写入速度和耐久性;同时,通过铁电晶粒尺寸调控和新型写入操作方案,有效抑制阵列单元扰动,在40nm垂直间距下实现阵列级扰动免疫。团队结合电学测试和纳米尺度材料表征,深入揭示了器件性能关联的物理机制。该工作在阵列层面展示了兼具速度和密度优势的新型三维存储技术,并实现了记录级的关键可靠性指标,综合性能达到国际领先水平。
该工作以“3D Vertical FeFET Array with Record Endurance (>1012), Fast Writing (±2V, 20 ns), Disturb Immunity, and Kb-scale Verification for High Density 1T RAM” 为题发表,北京大学集成电路学院博士生周粤佳为论文第一作者,唐克超研究员为通讯作者。
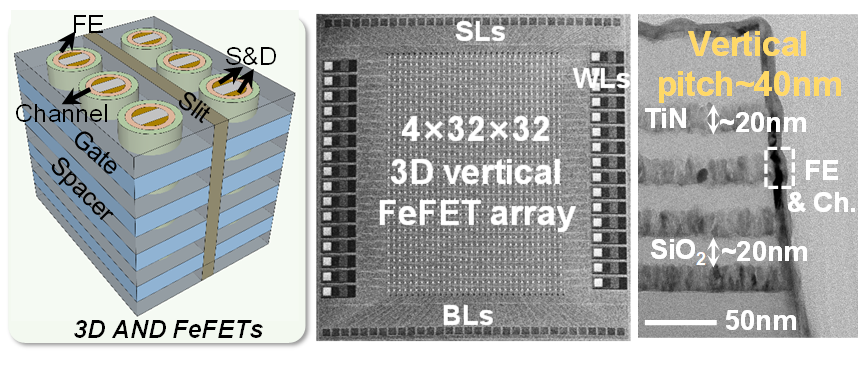
图1.1:3D FeFET的结构示意图和实验制备的Kb规模阵列

图1.2:3D FeFET的高速度、高耐久性能和阵列级读写展示
二、高压氮化镓单片双向开关器件技术
横向结构氮化镓功率器件可通过共享漂移区实现双向耐压,具有低导通电阻与低寄生效应等优势,推动了单片集成双向开关的快速发展。然而,高压氮化镓双向晶体管存在电场集聚问题,不仅会导致器件提前击穿,还会诱发高场陷阱效应,加剧动态导通电阻退化。
针对上述难题,魏进研究员团队提出了一种集成栅极终端扩展(GTE)结构的氮化镓双向开关器件。关态耐压条件下,GTE层的辅助耗尽作用可有效削弱电场尖峰,显著提升器件耐压能力;与传统双向晶体管相比,该新型器件的击穿电压提升40%。当漂移区间距为62μm 时,器件双向击穿电压可达±7874V,功率品质因数高达2.39GW/cm²,为目前已报道集成型双向器件中的最高纪录。此外,该新型器件可有效抑制动态导通电阻退化效应:在150 ℃环境下经2 kV高压应力测试后,器件归一化动态导通电阻低至1.43,这是国际上首次在氮化镓双向器件中报道高达2 kV电压应力下的动态导通电阻特性。
相关研究成果以“6.5 kV Enhancement-Mode GaN Monolithic Bidirectional Switch (MBDS) Achieving Record Power Figure of Merit”为题发表,北京大学集成电路学院博士生杨俊杰、余晶晶为论文共同第一作者,魏进研究员为通讯作者。
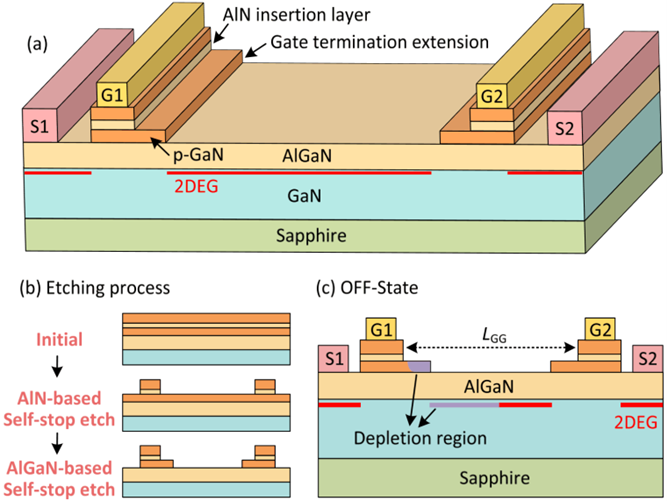
图2.1:新型氮化镓集成双向开关器件结构示意图

图2.2:制备器件的SEM和TEM图像
三、面向端侧Reasoning推理大模型的NPU加速架构与芯片
近年来,大语言模型(LLM)的能力提升越来越依赖以监督微调(SFT)和强化学习微调(RLFT)为代表的"后训练"。RLFT 让模型依据自身输出的反馈持续优化,是 DeepSeek-R1、Qwen3 等推理大模型获得强大数学、代码推理能力的关键,其完整闭环包含模型推理生成、奖励模型(RM)打分、梯度更新三步。然而已有的 LLM 加速芯片大多只面向单一的推理或 SFT 环节,难以在端侧闭合"生成-打分-更新"全流程:推理产生的 KV 缓存急剧膨胀、奖励模型打分计算量大、模型更新引入大量片外访存,成为三重瓶颈。
针对以上问题,贾天宇研究员团队研制了一款支持推理大模型与强化学习微调的高能效加速芯片。该芯片通过两级KV缓存压缩器(TLCC)在 token 与比特两级压缩缓存,实现 2.03× 的 KV 缓存压缩;通过基于最小哈希的打分单元(MHSU)以哈希碰撞高效近似余弦相似度,使奖励模型打分时延降低 2.27×;通过脉冲驱动的预测式更新引擎(PGFE)跳过数值微小的梯度并规避昂贵的片外转置访存,使权重更新运算量降低 3.79×、而精度仅损失 0.22%。芯片采用 22nm 工艺,面向 Qwen3-4B、DeepSeek-Math-7B 等推理模型实现了 68.95 TFLOPS/W 的片上能效与 122.2 μJ/Token 的系统能效,单次 RLFT 迭代时延 747.2 ms,是首款同时支持推理大模型与强化学习微调的加速芯片;相比已有的 SFT 加速器能效提升 1.26–2.59×,并使端侧 RLFT 后的模型准确率较预训练模型提升 6.46–24.11%,展示了"边推理、边自我提升"的端侧持续学习潜力。
该工作以"A 122.2μJ/Token Reasoning LLM Accelerator with Reinforcement Fine-Tune Featuring Two-Level KV-Cache Compression and Spike-Driven Predictive Update"为题发表于今年 VLSI 会议上,北京大学集成电路学院博士生李明轩、任文捷为论文共同第一作者,贾天宇研究员为通讯作者。
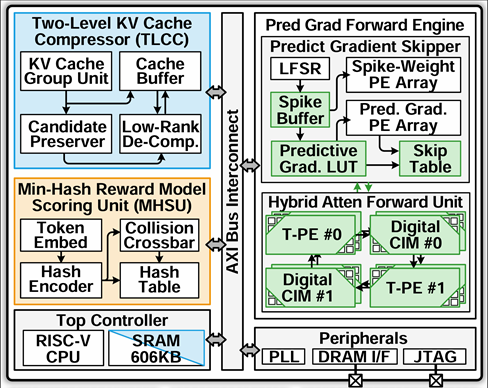
图3.1:Reasoning NPU芯片架构总览
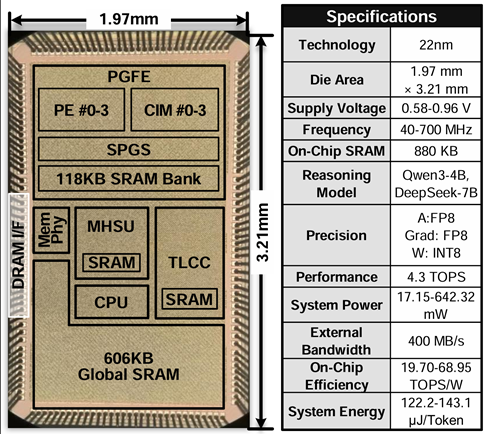
图3.2:芯片显微照片与规格
四、面向闭环DBS的多通道记录-刺激一体化神经探针芯片
脑深部刺激(Deep Brain Stimulation, DBS)是治疗神经系统疾病的重要技术之一。面向闭环 DBS 的植入式神经接口需要同时实现神经信号记录和自适应电刺激,对芯片的通道密度、功耗、面积、噪声和系统稳定性提出了很高要求。
针对上述挑战,鲁文高研究员团队提出了一款面向闭环DBS的 256 通道神经探针芯片,在单根探针上集成 252 个记录通道和 4 个刺激通道,并在每个记录通道内嵌入低功耗ADC。芯片同时支持神经记录、基线漂移抑制以及刺激过程中的同步监测。在电路实现方面,该工作提出了一种基于双环振荡器(Dual-Loop Oscillator, DLO)的时域ADC架构,实现高密度、低功耗的逐通道集成。在模拟神经溶液测试中,该芯片完成了神经波形记录和刺激验证。测试结果显示,该芯片平均每通道功耗为 4.32 μW,在 10-kHz 带宽下实现 3.68 μVrms 输入参考噪声,达到了国际领先水平。
该工作以 “A 4.32uW/Ch 256-Channel Neural Probe Integrating in-situ ADC and Stimulation for Closed-Loop DBS” 为题发表,并被选为Demo paper在Reception session进行现场演示。北京大学集成电路学院硕士生孙诗卉为论文第一作者,卓毅博士为通讯作者。
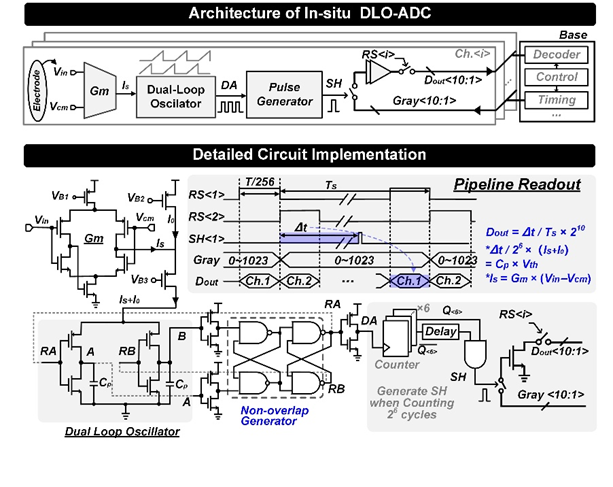
图4.1:基于双环振荡器的 in-situ ADC 电路实现
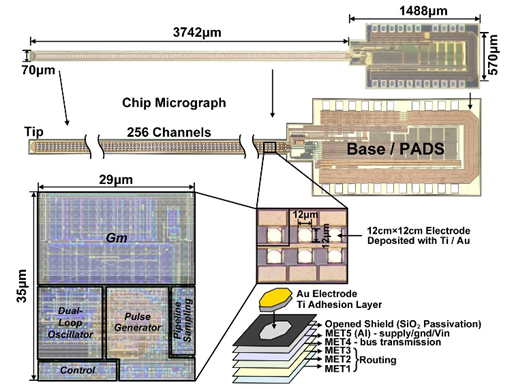
图4.2:256 通道神经探针芯片显微照片与通道布局
图4.3:Demo paper现场展示照片
背景链接
VLSI是超大规模集成电路和半导体器件领域里最顶尖的国际会议之一,是展现IC技术最新成果的重要窗口。该会议在国际集成电路/半导体器件的学术界以及工业界均享有很高的学术地位和广泛影响,会议文章不仅需要学术上的创新,更需要体现成果的产业价值和技术前沿性。每年英特尔(Intel)、美光(Micron)、三星(Samsung)、IMEC和台积电(TSMC)等国际知名半导体公司都在该会议上发布各自最新研究进展。2026年VLSI会议的主题为“用集成电路的创新推动人工智能前沿”,以下是入选文章的现场报告照片,以及北京大学部分参会师生与校友的合影。











