一键部署LLM混合精度推理,端到端吞吐比AWQ最大提升6倍!
清华大学计算机系PACMAN实验室发布开源混合精度推理系统——MixQ。
MixQ支持8比特和4比特混合精度推理,可实现近无损的量化部署并提升推理的吞吐。
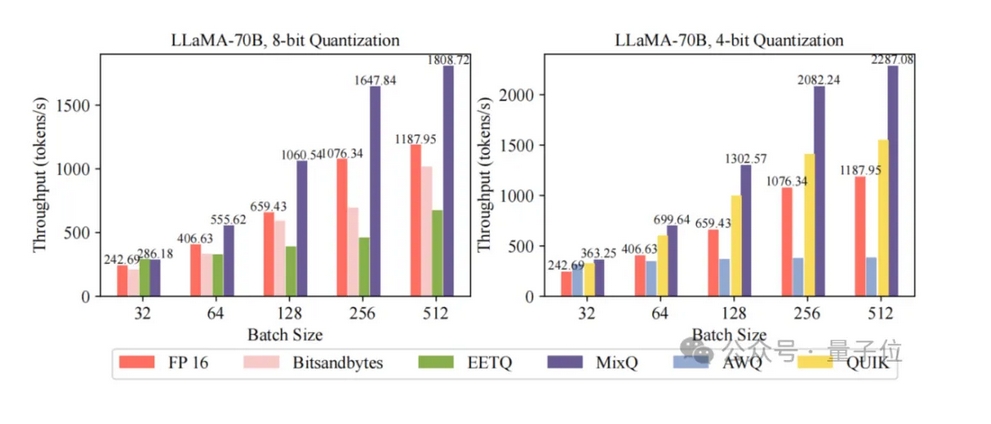
△图1 MixQ吞吐与已有开源工作比较
MixQ同时量化权重和激活,使用低精度张量核心(INT8/INT4 Tensor Core)实现推理加速;同时,MixQ提取激活中少量的离群值,使用高精度张量核心(FP16 Tensor Core)保持推理准确性,通过系统优化掩盖高精度访存开销。
不仅保持推理的准确性,而且通过使用低精度算力有效提升吞吐,充分发挥硬件计算潜力(图1)。
同时,研究团队提供了基于VLLM和Tensorrt-LLM的混合精度推理,用户可以方便地一键部署模型。
MixQ已支持多个主流大模型LLaMA3,Qwen2,Baichuan2,ChatGLM等。据了解,目前MixQ开源技术已被清程极智等AI行业公司应用在实际产品中。
该工作同时于高性能计算领域顶级国际会议SC’24发表,第一作者清华大学博士后陈逸东、通讯作者为翟季冬教授。
研究背景:已有量化技术总结
量化的主要技术路线有两条,第一条是权重量化。
权重量化的理论加速比是16/量化的比特数。例如,将模型压缩成为4bit,那么理论加速比为16/4=4倍。
然而,当服务商面临大量的用户同时访问时,权重量化的系统吞吐会低于FP16的吞吐,其主要原因是权重量化计算过程中将低精度权重恢复成FP16然后计算,这导致权重量化并不使用低精度算力,当场景表现为compute bound的时候,性能较低。
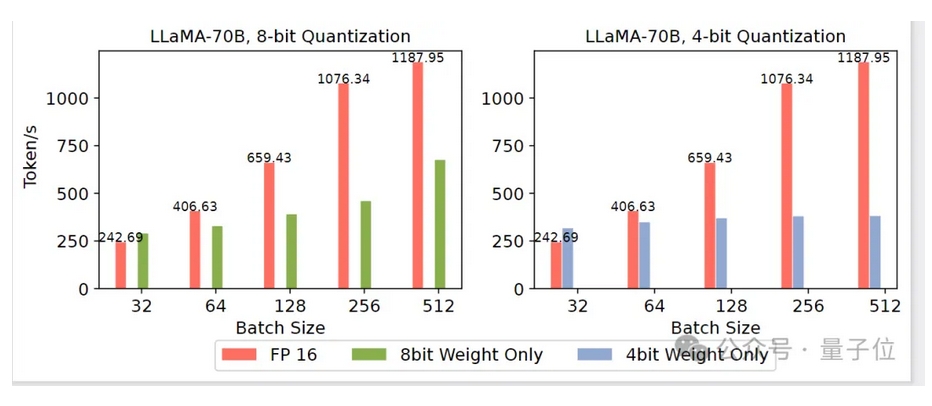
△图2 用户请求多权重量化吞吐低于FP16
第二条技术路线是量化权重和激活,使用低精度的张量核心来提升系统的吞吐。
直接将激活量化为低比特可能会出现较大的精度损失。其原因在于激活矩阵中存在离群值(图3)。
一个有效的方法是SmoothQuant,主要思想是通过平滑激活矩阵来降低量化激活的误差。
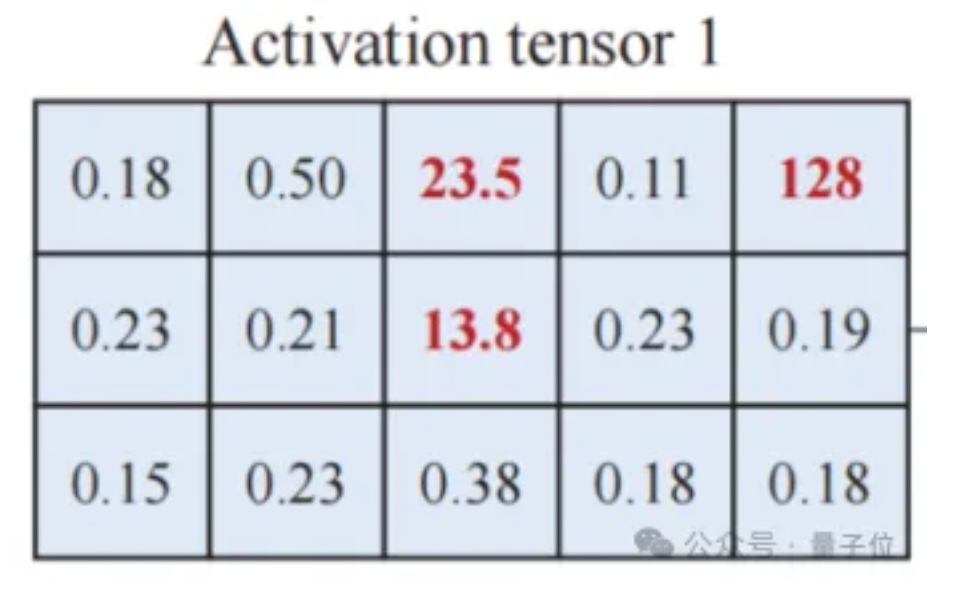
△图3 激活矩阵中存在离群值
混合精度量化则是一类全新的量化方法,该方案先做了一个矩阵分解,对绝大部分权重和激活用低比特存储,将离群值用FP16存储,分别做矩阵乘法。
混合精度量化的一个优势就是可以实现近乎无损精度的量化。使用混合精度量化的LlaMA模型在MMLU 20个领域上的数据集进行推理准确率测试表明,采用8bit混合精度量化后的准确率下降不到0.1%:
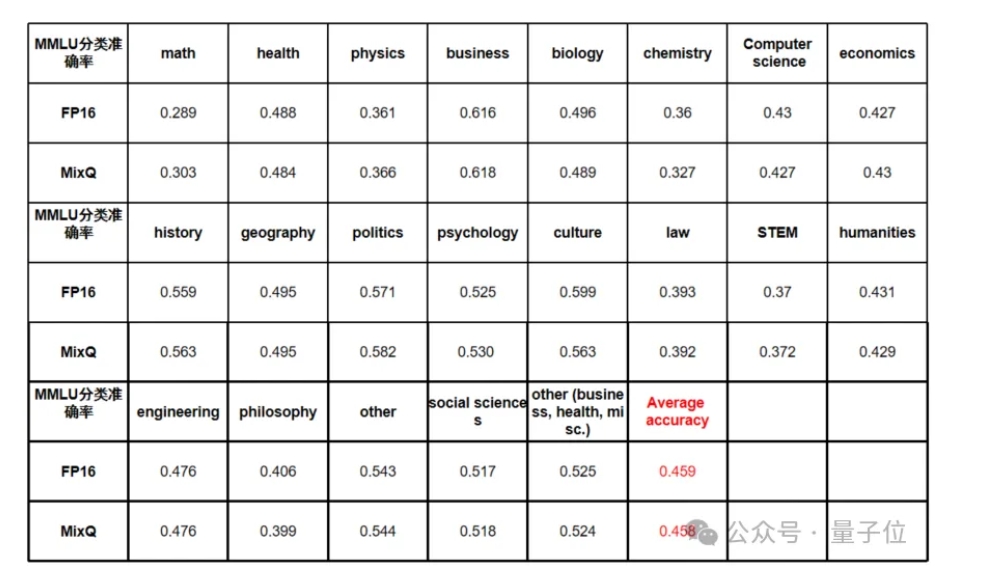
△图4 混合精度量化分类准确率
不过,此前已有的混合精度量化的系统的性能普遍不高,主要瓶颈在针对离群点进行查找、访存和计算的开销占比大。
以混合精度库Bitsandbytes为例,实测试表明,Bitsandbytes在用户请求数量为512时仅有1.08倍的加速。
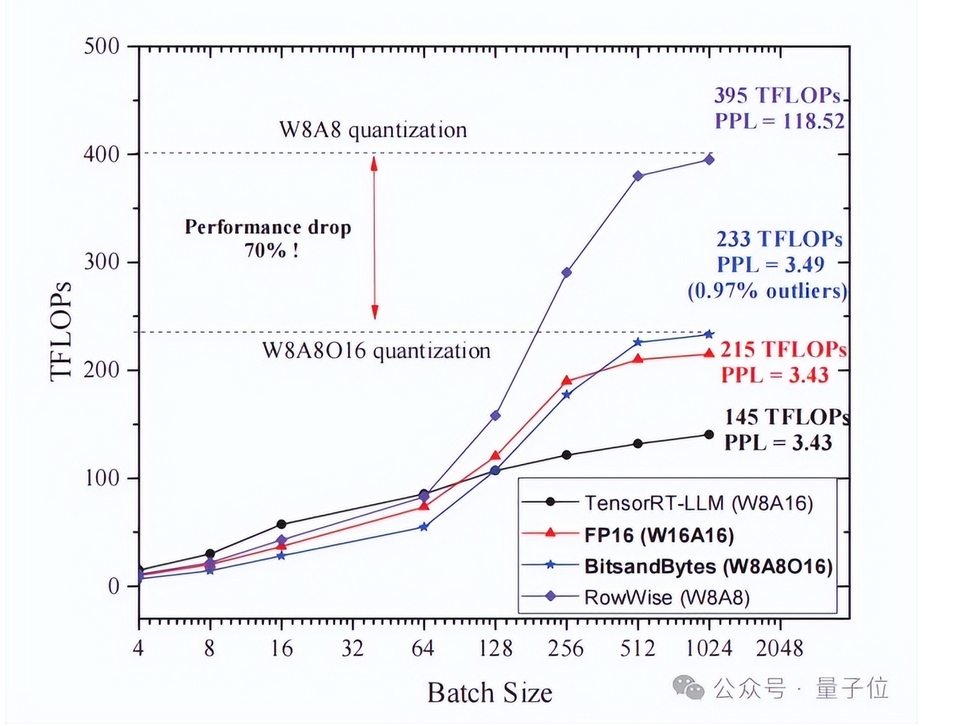
△图5 Bitsandbytes的在LLaMA70B上的Kernel性能测试
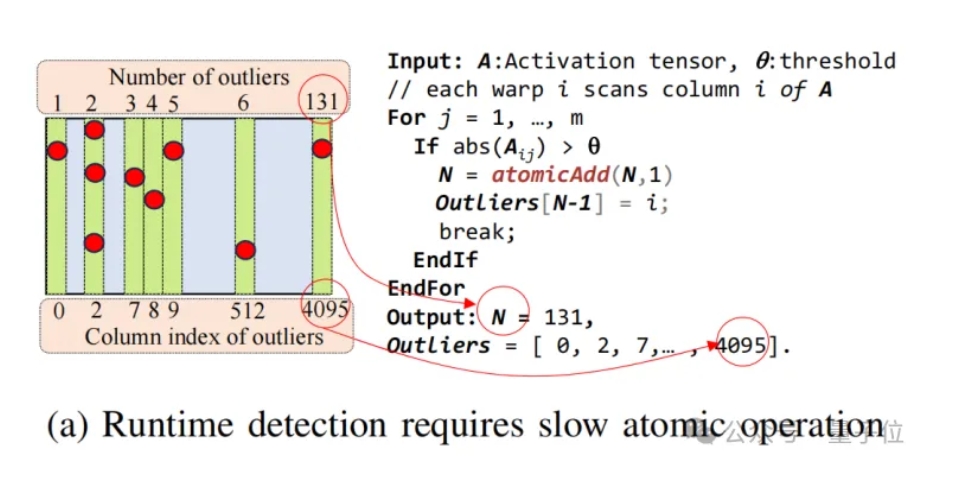
△图6 Atomic operator是混合精度推理系统的瓶颈之一
那么,如何优化对离群点的查找、访存和计算的开销呢?
MixQ的解决方案
MixQ的核心思想是基于离群点的局部性对混合精度的计算图做等价变换,使得变换后的混合精度的计算图可以避免离群点查找的额外开销;在此基础上,通过图层融合和设计高效的混合精度数据结构降低访存开销;最后通过CUTLASS生成高性能的混合精度算子,达到提升系统性能的效果。
MixQ的设计基于以下的观察:
离群点的局部性。对LLM的激活矩阵分析发现,在不同的decode阶段的离群点的分布是有规律的。
如图7,红色的点表示的是第一次出现的离群点,绿色的点表示的是重复出现的离群点,随着decode的进行,多数离群点出现在了固定的channel。
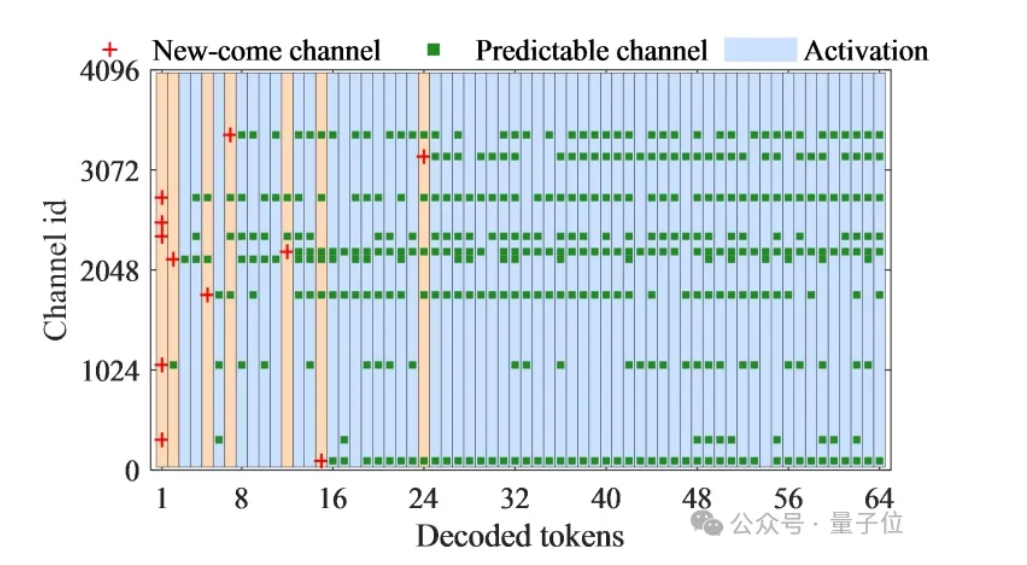
△图7 decode阶段离群点的分布规律
因此,研究人员得到一个重要的结论:在大部分的decode阶段是不需要重复检测离群点的,也就是说我们可以避免检查离群点的开销。
剩下的问题是,如何知道哪些时候不需要重复检查离群点呢?这个答案就隐藏在量化系数中。
在量化的过程中需要对矩阵进行amax的操作。因此,通过amax得到的结果可以判断矩阵中是否存在离群点。如amax的值大于阈值,那矩阵中存在离群点。反之则不存在。
更重要的是,amax操作可以和前一个操作融合。这样不仅以极低的代价检测离群点的存在,还通过对图层进行融合来降低量化的开销。
基于以上的分析,MixQ的设计使用了三个关键技术:
一是对计算图的等价变换。
针对混合精度的计算逻辑进行了等价变换以后,通过计算激活矩阵的amax的值,避免了检测离群点的开销。
二是设计混合精度数据结构。
MixQ将离群点“拼接”成了一个新的矩阵。这一方法相较于ATOM采用的重排列(reorder)具有更低的开销。
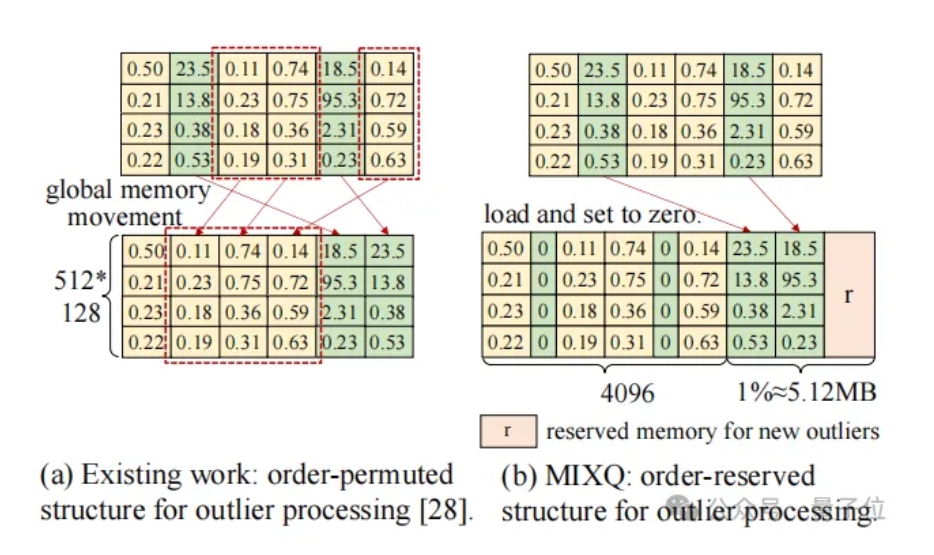
△图8 MixQ:order-reserved数据结构
三是使用CUTLASS编写高性能的混合精度的算子,这一关键技术的实现依赖于NVIDIA提供的高性能矩阵乘法模板CUTLASS 3.x。
MixQ在寄存器中反量化低精度的计算结果并与高精度的结果进行相加。
下面来看MixQ的实验结果,以LLaMA 70B为例。
在准确率表现方面,MixQ的准确率和Bitsandbytes一致。
在性能表现方面,MixQ 8bit kernel是Bitsandbytes的1.9倍。
MixQ 4bit Kernel的性能达724TFLOPs,是FP16的3.13倍。
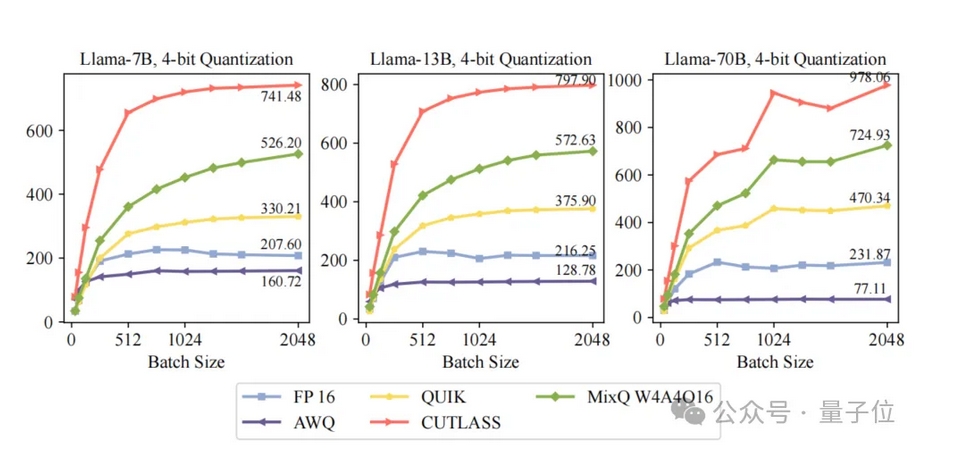
△图9 MixQ Kernel性能
端到端测试下,MixQ在batch=512相对Bitsandbytes和AWQ加速1.78和6倍。
项目地址:
[1]https://github.com/Qcompiler/MixQ_Tensorrt_LLM
[2]https://github.com/Qcompiler/MIXQ
[3]https://github.com/Qcompiler/vllm-mixed-precision