
随着人工智能技术的迅速发展,近年来AI计算需求呈爆炸式增长。为了满足这一需求,越来越多的公司和研究机构开始关注专用处理器的开发,其中,神经网络处理单元(NPU)因其在处理深度学习任务方面的高效性而受到广泛关注。
然而,尽管NPU在某些特定任务中表现出色,独立发展的可能性却受到质疑。不久前,刚刚获得1亿美元投资的Imagination便突然决定放弃独立开发三代的NPU IP,转而将类似的功能添加到其GPU产品中。
Imagination新任创新和工程主管Tim Mamtora直言:“和其他所有公司一样,我们看到了NPU的潜力就想着‘是的,我们应该做其中一种’。但在开发出表现出色的硬件后却出现各种问题,与之配套的软件堆栈是什么?我们如何向我们的客户和开发人员展示它等等。”
作为曾经博通IC设计部门的总工程师,Tim Mamtora认为开发AI加速器是非常困难的,尤其是考虑到AI模型和框架的演进速度以及AI软件基础设施的碎片化状态。可以说,AI软件堆栈方面的挑战才是导致Imagination决定停止开发NPU的真正原因。
此前被大多数人寄以厚望的NPU,其局限性正逐渐暴露出来。
NPU独立工作的局限性
众所周知,NPU是一种专为神经网络计算而设计的处理器,具备高并行度和低功耗的特点。它的架构通常针对矩阵运算进行了优化,这是深度学习模型训练和推理中常见的运算类型。然而,NPU在独立工作时也存在一些局限性。
NPU主要针对深度学习任务进行优化,尽管在特定的AI推理任务中表现卓越,但在处理其他类型的计算任务时,如图形渲染、传统数据处理等,NPU的能力却显得不足。这使得NPU在多样化应用场景中的适用性受到限制。
在生态方面,目前NPU的生态系统相对较小,开发者面临的工具和框架选择较少。这导致NPU的推广和应用受到不小的阻碍,企业往往需要同时开发和维护多个处理器,这加大了开发和运营的复杂性。Imagination对此深有体会,因为迁移和优化最终客户的算法并在产品的整个生命周期内提供支持,这是一件非常具有挑战性的事。据Mamtora透露,Imagination的一些NPU IP的客户希望为下游客户定制软件,他们又不得不将这方面的技术支持推回给 Imagination。
另外,尽管NPU在AI计算中具有潜力,但市场对新技术的接受需要时间。许多企业在决策时仍倾向于使用成熟的GPU,特别是在需要图形处理的应用中,而在大多数应用中,图形处理都是必不可少的。
NPU发展的正解
在当前的市场上,提及NPU技术的发展,则不得不联想到一家国内的IP供应商芯原股份。在接受集微网采访时,芯原股份执行副总裁、IP事业部总经理戴伟进指出,公司用于人工智能的NPU IP已被72家客户用于其128款人工智能类芯片中,已在全球范围内出货超过1亿颗。
芯原股份真正开始NPU IP的开发实际是在2017年,戴伟进指出,当时一些采用芯原GPU IP的客户对芯片PPA提出了更高的要求,同时还需要有一定的可编程性。如果完全设计一颗高性能的ASIC芯片显然不符合可编程的特性,此外由于市场需求迅速迭代,ASIC芯片必须经历的研发生产周期将导致难以快速响应市场变化。于是,芯原便着手开发新的NPU IP以固化一部分AI计算功能,打造GPU+GPGPU+NPU的可扩展AI计算平台。
GPU IP作为芯原成熟的核心业务,已在图形渲染领域得到了广泛应用。而芯原的GPGPU IP在深度学习训练和推理中也同样表现优异。NPU、GPU和GPGPU的协同发展能够弥补彼此的短板,形成更强大的计算平台。
在复杂的AI任务中,NPU可以专注于执行深度学习模型中的特定运算,而GPU或GPGPU则负责处理图形渲染和其他计算任务。这种资源互补使得系统能够在多任务环境中表现更佳,从而提高整体效率。
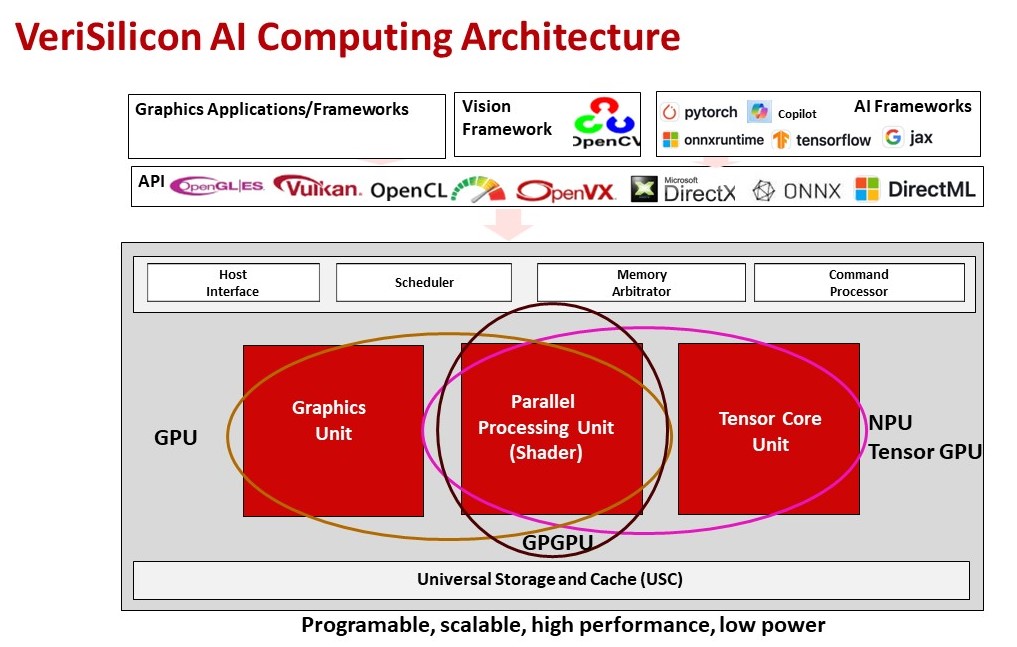
如上图所示,芯原的GPU、GPGPU和NPU紧密地结合在一起,三者的协同工作能够提供更大的灵活性。开发者可以根据实际需求选择最合适的计算资源,使得系统具有更好的可扩展性。这种灵活性在处理多样化的AI应用时尤为重要,尤其是在边缘计算和实时推理场景中。
戴伟进强调,三者的紧密结合主要体现在指令级融合,这种融合意味着三者在硬件层面上能够共享指令集,从而实现更高效的协同工作。
以芯原的VIP9X00CC为例,其实现GPGPU模块和NPU模块的指令级融合,并采用SIMT(单指令流多数据流)并行计算架构,允许单个指令同时对多个数据元素进行操作。这种架构通常用于GPU,使用SIMT架构使得在执行AI计算任务时,能够实现更高效的并行处理。
VIP9X00CC还支持DLP/ILP/TLP并行性,保证NPU和GPGPU能够灵活地处理不同类型的并行计算任务。
戴伟进进一步指出,芯原NPU的设计包含了多年的优化经验,特别是在数据组织、压缩、迁移和计算方面,而VIP9X00CC将NPU的设计理念和GPU的并行计算能力相结合,大幅提高了整体的AI计算效率。
值得一提的是,VIP9X00CC中NPU和GPGPU还共享内存和常量寄存器,共享内存资源对于提高数据处理速度和减少内存访问延迟非常重要。
“面对所有的计算需求,我们的软件能够将其按运算类型的不同来进行分类,并同步分配给对应的NPU或GPGPU模块快速完成运算,”戴伟进指出,“但如果是独立的两颗NPU和GPGPU,则意味着大量的数据交互和额外的内容转化成本。”
至于戴伟进提到的软件,也是Imagination独立发展NPU业务的核心痛点,芯原是如何做到的呢?戴伟进表示,芯原依据多年经验建立了完整的软件体系,芯原Acuity工具、库和软件堆栈能够支持,且不论是端侧还是云侧,芯原都采用通用的软件栈。
芯原的AI计算框架支持多种图形API,如Microsoft DirectX、Microsoft DirectML、Vulkan、OpenGL、OpenGL ES等;支持SYCL、OpenCL、CUDA等并行编程模型;同时也支持多种AI和机器学习框架,如PyTorch、PaddlePaddle、ONNX Runtime、JAX、TensorFlow等。这种广泛的支持使得芯原的NPU IP能够适应不同的AI应用需求,这种融合不仅降低了开发者的学习成本,也有助于提升NPU的市场接受度。
也正因如此,芯原的NPU IP才会在市场上获得亮眼表现。而关于未来的NPU市场前景,戴伟进认为,随着人工智能从云端走向边缘端,NPU将迎来更加明显的爆发式增长。
从云到边缘,NPU的黄金时刻
随着人工智能应用的普及,数据隐私和实时处理的需求推动了边缘计算的发展。NPU可以在边缘设备上提供高效的AI计算能力,满足这些需求。
例如AI PC、AI Phone的问世,以及智慧AR眼镜、智慧驾驶汽车开始导入人工智能,大型AI模型正逐渐被优化以适应边缘设备。而NPU可以专门针对这些优化后的模型进行加速,提供更好的性能和效率。
同时,NPU还可以为特定的AI工作负载提供定制化的硬件加速,这对于执行特定任务(如图像识别、语音处理)的边缘设备来说是一个重要的优势。在边缘设备上,能效比是一个关键考虑因素。NPU的设计可以针对AI工作负载进行优化,以提供更高的能效比,这对于电池供电的设备尤为重要。因此,戴伟进认为,智慧AR眼镜、智慧家居等领域,NPU还将迎来一波发展机遇。
另外,面临庞大的AI计算需求,分布式计算将成为更好的选择。而NPU可以在不同的计算节点上提供协同工作的能力,使得AI应用可以在多个设备之间实现高效地分配和执行。所以在整个从云到端的全流程中,NPU都将得到充分的市场空间。
在这样一个肉眼可见的高速增长阶段,戴伟进认为,芯原以及其他NPU供应商不仅需要加大投入以保证技术优势,也需要及时针对流行的AI算法和模型进行优化,确保NPU能够高效运行最新的AI应用。此外,还需要保证可扩展性,提供不同性能和功耗级别的NPU产品系列,以满足从高端服务器到低端IoT设备的复杂需求。
小结
在AI计算的浪潮中,NPU的发展正迎来新的转折点。Imagination的决定提醒我们,独立工作的NPU并非AI计算的正解,还是需要与GPU等协同工作,方能实现最佳的性能和效率。
芯原股份的成功案例为我们提供了宝贵的经验。它通过构建一个包含GPU、GPGPU和NPU的可扩展AI计算平台,实现了不同计算资源的有机结合。这种融合策略不仅提升了AI计算的整体性能,还为客户提供了更大的灵活性和可扩展性,以适应不断变化的市场需求。
面向未来,NPU的发展需要更加注重生态系统的建设。这意味着不仅要在硬件上进行创新,还要在软件工具、开发框架和支持服务上进行投入。通过构建一个健康、开放的生态系统,NPU技术才能更好地融入各种应用场景,满足不同客户的需求。
总之,NPU作为AI计算领域的重要参与者,其未来发展将更加依赖于与其他处理器的协同和生态系统的完善。只有在硬件、软件和生态系统上实现全面优化,NPU才能在AI计算的浪潮中立于不败之地。









