

过去十年,智能终端的AI能力逐步提升,特别是近年来受到生成式AI浪潮的推动,终端AI进入到全新的发展阶段,从早期的图像处理到手机助手,带来终端交互和体验上的颠覆式变革。
在这个过程中,NPU以及异构计算作为终端AI的算力基石底座,发挥了重要作用,有力地支持和推动了终端AI以及生成式AI的广泛规模普及,持续进化引领着智能手机行业创新的方向。
作为终端AI的赋能者,十余年来,高通始终致力于终端AI技术的创新,持续保持在传统AI以及生成式AI时代的行业领先地位。这家以让智能计算无处不在为愿景的创新公司,正通过NPU和异构计算,推动终端AI不断达到新的高度。
手机AI,谁才是起点?
NPU(Neural network Processing Unit,即神经网络处理器)是专门用于处理AI负载的硬件,在行业引起广泛关注在2016年前后。
彼时,寒武纪发布全球首款商用终端AI处理器,在运行计算机视觉、语音识别、自然语言处理等智能处理关键领域,性能、能耗等均全面超越传统CPU和GPU,由此拉开终端AI的序幕。
出于商业等因素的考虑,形式上看,NPU并未成为厂商们的统一称谓,但实质上,通过设计专用硬件处理相关AI工作负载已经成为手机处理器设计中的趋势以及塑造差异化竞争力的显著标签。
随后,一些具有自研芯片优势的系统整机厂商迅速推出相关产品。2017年,通过和寒武纪的合作,华为Mate10中搭载的麒麟970中首次集成AI模块,苹果推出搭载AI仿生引擎的Iphone X,手机AI元年自此开启。
2018年,联发科推出AI平台NeuroPilot,整合了AI处理器APU。三星在推出的Exynos 9820中首次搭载NPU,智能手机全面进入AI时代,智能相册分类、APP预加载等功能出现,人脸识别、深度学习等AI技术开始广泛在智能手机应用中落地。
芯片、手机领域的快速发展和激烈竞争,大量的复制、营销和包装下的结果是很容易让人们忽视掉这个行业真正的原始创新者。
事实上,率先提出并应用NPU概念的并非是华为和苹果,而是高通。

2013年,高通推出首款量产采用创新架构设计的处理器Zeroth。Zeroth的结构完全不同于当时的骁龙系列芯片,而是更接近于用电路对生物神经细胞进行模拟,从而在智能终端上实现近似生物神经网络的智能感知与判断操作。
彼时,高通便将这一新的处理架构称之为NPU。通过Zeroth,高通能够将机器学习等能力引入到移动平台,包括通过对人脸和物体识别进行图像自动分类,也可以通过传感器实现对周围环境的监控输入,同时终端运行也实现了对于用户隐私的保护。

2015年发布的骁龙820中首次集成高通AI引擎
2014年,高通收购AI图像识别技术公司Euvision,进一步探索AI在移动端的潜在用例,并在随后将源于Zeroth的AI加速架构引入到2015年推出的骁龙820移动平台的设计之中,支持图像,音频和传感器运算,以此奠定了骁龙系列高通AI引擎的基础,骁龙820也是首次集成高通“第一代AI引擎”的移动平台。
是的,如你所见,十年前高通的Zeroth,才是移动终端NPU的祖师爷。而在2007年,高通便启动了首个AI研究项目,首款Hexagon DSP在骁龙平台上正式亮相——DSP控制和标量架构成为高通未来多代NPU的基础。
此后,高通便始终主导和推动着NPU领域的创新,紧跟终端AI行业的技术演进方向和需求,不断提升和丰富NPU的特性和功能。
2018年,高通在骁龙855上中为Hexagon NPU增加了Hexagon张量加速器。2019年,高通在骁龙865的拓展了终端AI用例,包括AI成像、AI视频、AI语音和始终在线的感知功能。
2020年,高通为Hexagon NPU带来了变革性的架构更新。融合了向量、张量、标量加速器,实现更好的性能功耗表现。同时还为加速器打造了专用大共享内存,让共享和迁移数据更加高效。这种融合AI加速器架构为高通未来的NPU架构奠定了坚实基础。
2022年,骁龙8Gen2中的Hexagon NPU实现了众多重要技术的加强。包括能够根据工作负载动态适配供电的专用电源传输轨道。最大化利用NPU中的标量、向量、张量加速器并降低功耗的微切片推理。提升能效和内存带宽效率的INT4;用于加快生成式AI的多头注意力机制的推理速度的Transformer网络加速;以及包括优化了的分组卷积、激活函数和张量加速器性能的其他特殊硬件等。
2023年,高通在骁龙8Gen3中,又进一步升级了NPU微架构以及相关能力,为持续AI推理带来98%性能提升和40%能效提升,从而实现对于生成式AI的更好支持。

如何打造一颗优秀的NPU?
十余年来,得益于NPU和异构计算领域的开拓性创新,高通构建起在终端AI侧的行业领导力,在生成式AI时代,这一优势进一步凸显。

生成式AI的快速发展,带来不同场景下用例的多样化计算需求,传统的以通用计算为目的的CPU、GPU难以满足。
比如,当前AI用例需求主要体现为三类:
一是按需型。需要立即响应用户需求,如图像生成、编辑、代码生成、摘要、文本创作等。
二是持续型。对于运行时间较长的用例,如语音识别、超级分辨率、视频语音通话处理及实时翻译等。
三是泛在型。用例在后台持续运行,包始终开启的基于情境感知的AI个性化助手等。
对于上述用例,传统的通用CPU和GPU很难满足其所带来的功耗和热限制。此外,用例也将会不断拓展,在功能完全固定的硬件上部署并不实际。因此,需要以AI为中心定制设计全新的计算架构,包括面向生成式AI全新设计,专为实现低功耗加速AI推理而打造的NPU,并与AI行业的发展方向保持一致。
如何设计一个优秀的NPU产品?高通给出的答案是:系统级解决方案、定制化设计和快速迭代创新。这也是其Hexagon NPU的显著差异化竞争优势。
首先,系统级解决方案有助于构建起芯片设计的全局视角,考量每个处理器的架构、SoC系统架构和软件基础设施。从而能够发现当前和潜在的瓶颈,并在增加或修改硬件方面做出恰当的权衡和决策。通过跨应用、神经网络模型、算法、软件和硬件的全栈AI研究与优化全面实现。
第二,需要具备定制化设计的能力以及控制指令集架构(ISA),从而使架构师能够快速进行设计演进和扩展以解决瓶颈问题。
第三,上述迭代改进和反复循环,使得高通能够基于最新神经网络架构持续快速增强高通NPU和高通AI软件栈。基于高通的自主AI研究以及与广大AI社区的合作,使得能够与AI模型的发展保持同步。高通具有开展基础性AI研究以支持全栈终端侧AI开发的独特能力,可赋能产品快速上市,并围绕终端侧生成式AI等关键应用优化NPU部署。
因此,历经多代演进的NPU,利用大量的技术创新和迭代成果消除瓶颈。例如,在骁龙8Gen3中,进行了诸多用于支持生成式AI大模型的架构升级。
比如,内存带宽是大语言模型Token生成的瓶颈,这意味着其性能表现更受限于内存带宽而非处理能力。因此,Hexagon NPU的设计中特别注意了提高内存带宽效率,骁龙8Gen3中,高通将Hexagon NPU中的专用共享大内存的带宽翻倍,此外,骁龙8Gen3还支持业界最快的内存配置之一:4.8GHz LPDDR5x,支持77GB/s带宽,从而满足生成式A用例日益增长的内存需求。
高通认为,从DSP架构入手打造NPU是正确的选择,可以改善可编程性,并能够紧密控制用于 AL处理的标量、向量和张量运算。高通优化标量、向量和张量加速的设计方案结合本地共享大内存、专用供电系统和其他硬件加速,让高通的解决方案独树一帜。高通NPU能够模仿最主流模型的神经网络层和运算,比如卷积、全连接层、Transformer以及主流激活函数,以低功耗实现持续稳定的高性能表现。
异构计算:推开终端AI的大门
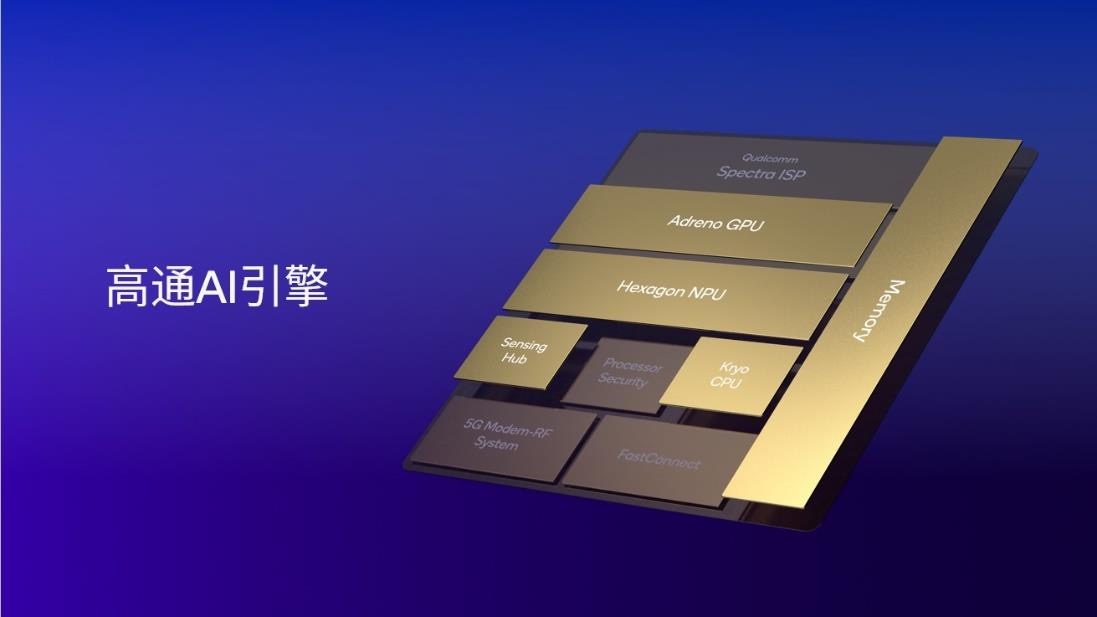
以AI为中心,高通打造了行业领先的处理器异构计算架构——高通AI引擎,包括Hexagon NPU、Adreno GPU、Kryo CPU或Oryon CPU,高通传感器中枢和内存子系统。其中,Hexagon NPU是关键一部分,这些处理器为实现协同工作而设计,能够在端侧快速高效运行AI应用。
如今,适合在终端侧运行的生成式AI正变得更为复杂,参数规模也变得更加庞大,从10亿到100亿到700亿参数。他们正进入多模态阶段,意味着可以进行多样的输入,例如文本,语音,图像等,并生成多种输出结果。
这种带有复杂性、并发性和多样性的生成式AI负载,通常需要利用SoC中所有处理器的能力。因此,具备跨处理器和内核支持生成式AI的扩展能力,以及能够将生成式AI模型和用例映射至一个或多个处理器及内核的解决方案非常重要。

即异构计算系统解决方案需要针对不同负载的类型,选择合适的处理器。这其中涉及的因素包括用例、设备类型、终端层级、研发时间、关键性能指标、开发者专长等,系统设计方案需要在众多因素中间权衡。
如前所述,多数生成式AI用例能够分为按需,持续或泛在型。在按需型用例中,延迟是KPI,因为用户不想等待。当这些应用使用小模型时,CPU通常是最佳选择。当模型来到数十亿参数时,GPU和NPU更加合适。对于持续和泛在的用例,电池续航和能效往往是重要关键因素,此时NPU便成为最佳选择。
另一个关键区别在于AI模型为内存限制型(性能受到内存带宽的限制),还是计算限制型(性能受到处理器性能限制)。如今大语言模型在生成文本时都受到内存限制,因此需要关注CPU,GPU和NPU的内存效率。而对于大视频模型而言,更受计算和存储限制的,需要GPU和NPU支持,NPU能够提供最佳能效。
在2023年的骁龙峰会上,高通在搭载骁龙8Gen3的智能手机上,演示了语音控制的AI个人助手,支持手机屏幕上的虚拟化身实现实时动画效果。这个过程很好的展示了如何通过高通的异构计算解决方案实现针对AI用例和具体场景的设计。

1、当用户与AI语音助手交谈时,声音通过OpenAI的自动语音识别(ASR)生成式AI模型Whisper转换成文本,这个过程是在高通传感器中枢上运行的。
2、AI助手使用Llmam20-70亿大模型生成文本回复,该过程在NPU上进行。
3、利用在CPU上运行的开源TTS模型将文本转换成语音。
4、同时,虚拟化身渲染必须与语音输出同步,以获得足够真实的用户交互界面。借助于音频创建融合变形动画(blendshape),能够使嘴部和面部表情带来合适的动画效果。这种传统的AI工作负载在NPU上运行。
5、最终虚拟化身渲染过程在GPU上进行。以上步骤,数据都会通过内存子系统有效传输,并尽可能在芯片上保存数据。

生成式AI大放光彩,有龙则灵
凭借在NPU以及异构计算上的深厚积累,高通持续推动终端AI的落地以及规模普及,率先将大模型带入手机,也将AI PC的能力和水平提升到新的维度,持续引领生成式AI全面在中端落地,展现出骁龙平台领先的AI性能。
在去年2月的MWC上,基于骁龙8Gen2,高通首次进行了离线状态下,手机15秒内Stable Diffusion(文生图)演示。在2023年的骁龙峰会上,高通展示了两个生成式AI应用,表明了面向大语言模型和大视觉模型通用架构的真实应用性能。在骁龙8Gen3上,个人助手演示能够以高达每秒20个tokens的速度运行Llama2-7B。在不损失太多精度的情况下,Fast Stable Diffusion能够在0.6秒内生成一张512*512分辨率的图像,展现出在智能手机领域领先的Llama和Stable Diffusion模型指标。
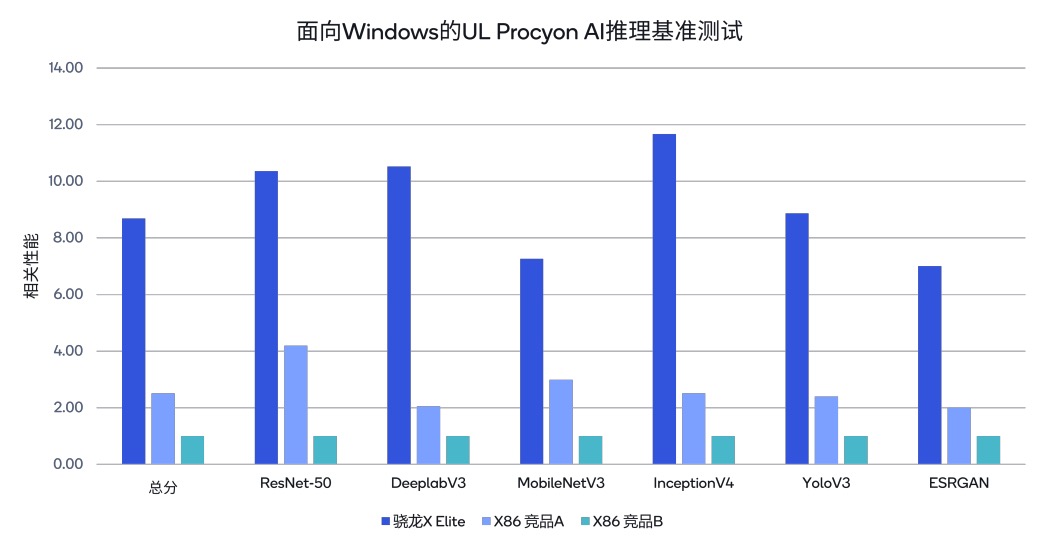
此外,高通去年还发布了专为AI PC打造的骁龙X Elite平台,它能支持在终端侧运行超过130亿参数的生成式AI模型。骁龙XElite 上集成的 Hexagon NPU 算力达到 45TOPS,大幅领先于友商最新 X86 架构芯片NPU 的算力数值。在面向 Windows 的 UL Procyon Al基准测试中,与其他 PC 竞品相比,骁龙XElite 具有领先的性能。例如,骁龙xElite 的基准测试总分分别为x86 架构竞品A的 3.4倍和竞品B的 8.6 倍。
今年MWC上,高通进行了全球首个在安卓智能手机上运行大型多模态语言模型的展示,以及高通首个在安卓手机上运行的LoRA模型,再次引领终端生成式AI的创新。在PC方面,高通在搭载全新骁龙X Elite平台的Windows PC上,进行了全球首次运行音频推理多模态大模型的展示。
在众多AI行业权威基准测试中,高通AI能力也均取得了领先的表现。
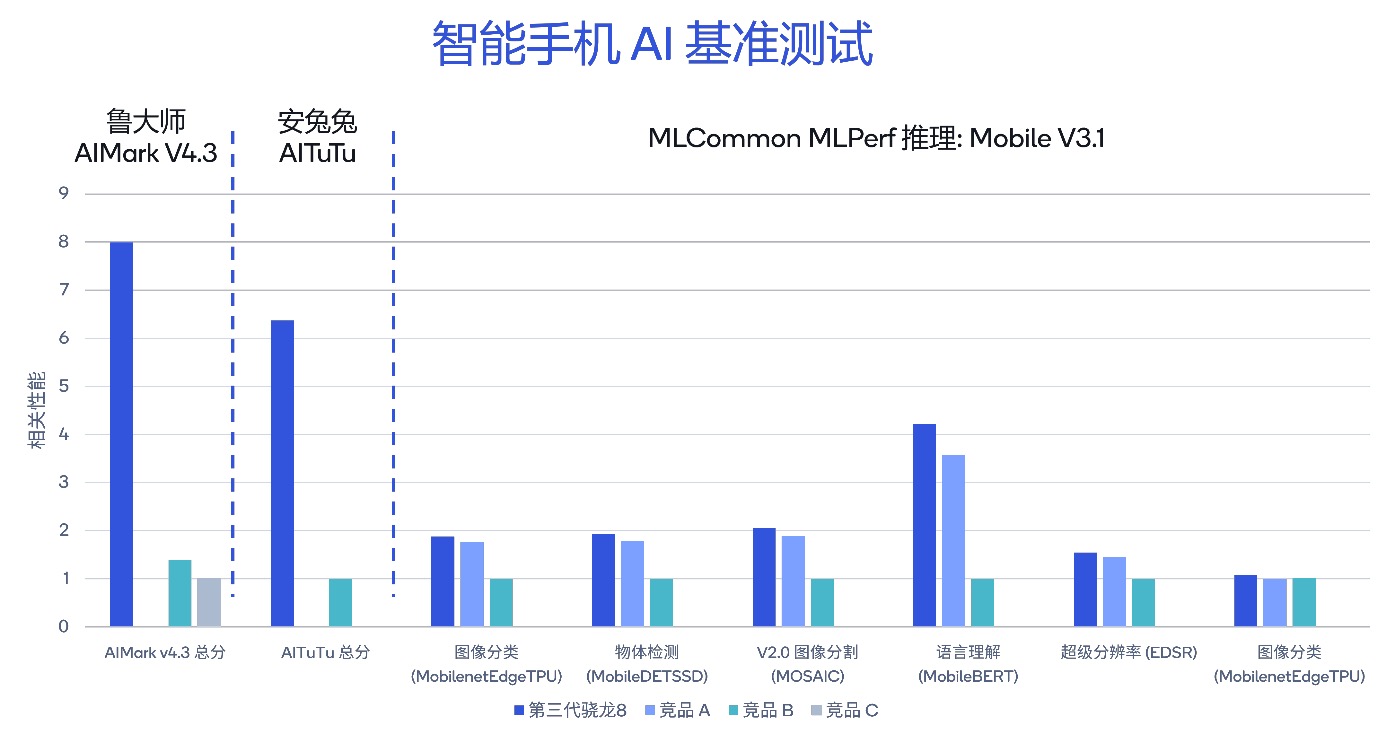
在生成式AI语言理解模型MobileBert上,骁龙8Gen3比竞品A高17%,比竞品B高321%。在鲁大师IMark V4.3基准测试中,骁龙8Gen3分别为竞品的5.7倍和竞品C的7.9倍。在安兔兔的AITuTu基准测试中,总分为竞品B的6.3倍。
高通AI领先的能力,除了优秀的硬件支持外,让开发者能够获得基于异构计算的AI加速,缩短开发时间,实现对于AI用例的快速部署,对于终端AI的规模化拓展也至关重要。
通过高通AI软件栈,高通将互补性的AI产品整合在统一的解决方案中。OEM厂商和开发者可以在高通的产品上创建,优化和部署AI应用,并利用高通AI引擎的性能,让开发者一次创造AI模型便可以部署在不同的产品上。
同时,高通发布AI Hub为骁龙和高通平台提供了超过75个优化AI模型,助力开发者轻松为Android应用程序添加个性化定制的终端侧AI,进一步缩短开发者部署生成式AI用例的时间,推动生成式AI在端侧的规模普及。

此外,在软件方面,还专注于AI模型优化以实现能效和性能的提升,包括量化、压缩、条件计算、神经架构搜索(NAS)和编译,在不牺牲准确度的情况下缩小AI模型,并使其高效运行。
综上,系统化的解决方案,定制化的设计思路以及快速的创新迭代,软硬件层面共同的创新和努力,构筑起高通在终端AI方面的护城河,形成显著的差异化竞争力,使高通在推动生成式AI开发和应用方面独树一帜,也在持续引领终端生成式AI的行业创新和技术发展方向。
智算无界,有龙则灵。








