

作者简介
Dr. Luo,复睿微电子英国研发中心GRUK首席AI科学家,东南大学工学博士,英国布里斯托大学博士后,常驻英国剑桥。长期从事科学研究和机器视觉先进产品开发,曾在某500强ICT企业担任机器视觉首席科学家。
Jane.Zhong,复睿微电子算法科学家,毕业于中科院高能物理所,曾就职于清华大学联合研究所,先后担任资深算法专家、系统架构专家,长期从事图像算法和人工智能领域科学研究工作。
自动驾驶ADS中与安全决策相关的一个最主要的风险是来自环境信息获取的不完全性,即小目标、遮挡、或感知野受限导致的部分可观察问题和对动态交通场景理解的不完整问题。在这种动态和不确定性的场景中,环境需要建模成部分可观察的Partial Observable Markov Decision Process (MDP)即POMDP,为了降低计算复杂度,一般都选择离散化空间或者部分连续空间来解决POMDP问题。对不确定性信息评估的一种常用的做法是对当前状态的概率分布进行构建,得到一个置信(belief)状态,这种形态可以通过离线或者在线构建。离线计算意味着,不是针对当前状态,而是面对所有可能的置信状态的最可能的行为,在线计算意味着需要在精度和效率之间做权衡。
上述的这种交互性决策控制,也是一个典型的多目标问题,这包括行驶的安全保证、整体效率和舒适体验。多目标包括数字化智能体(自动驾驶车辆AV),复杂和拥挤行驶场景中的行人、车辆、障碍物、交通标示物、动物等等。设计智能车辆AV安全行驶算法的理论基础,是通过构建多维感知+行为预测+运动规划的算法能力来实现决策安全的目的。而会影响到车辆在交互中决策控制的驾驶行为,包括驾驶者(人或AV)的社会层面交互和场景的物理层面交互两个方面:
· 社会层面交互:案例包括行驶车辆在入道、并道、换道、或让道时的合理决策控制,主车道车辆在了解其它车辆的意图后自我调速,给需要并换道的车辆合理让路来避免可能的冲突和危险。
· 物理层面交互:案例包括静态物理障碍(静态停车车辆,道路可行驶的边界,路面障碍物体)和动态物理线索(交通标识,交通灯和实时状态显示,行人和运动目标)。
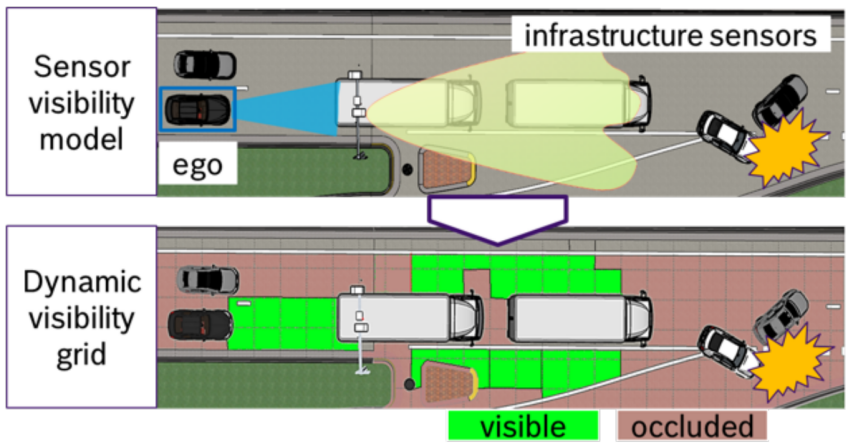
图 1ADS环境下能见度估计问题
综上所述,ADS面临的一个核心挑战是环境目标的感知融合问题,即需要通过多模态传感器的组合使用,在动态行驶场景中对3D/4D环境目标如何有效进行选择性感知融合的问题,这需要首先解决图 1中所示的传感器能见度(Sensor Visibility)问题,这可以涵盖如下几个子问题:
· 2D/3D目标识别(Object Detection)
· 空间占用映射(Occupancy Mapping)
· 盲区/非盲区度量(Blind Area Measurement)
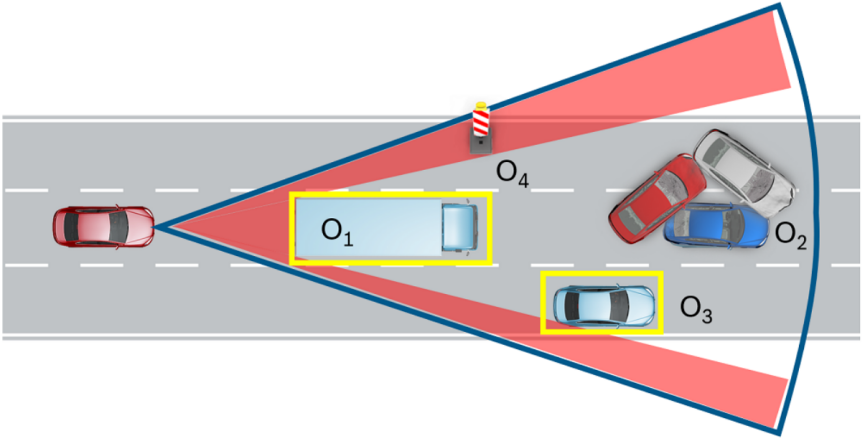
图 2 Example of FoV, Visibility and Detectability
显而易见,ADS的感知能力,依赖于观察区域的传感器能见度,来提供完整的场景语义理解,这包括多目标的结构化信息提取,以及隐特征Latent空间的非显性特征表达。Camera由于能够提供丰富的语义信息和近似的时空深度信息,能见度建模多数是针对多摄像头设置下的场景覆盖Coverage,指的是指无遮挡下的视场角Field of View (FoV)和有动静态遮挡物遮挡下的视线Light-of-Sight,一般多指的是后一类。场景覆盖可以通过光线跟踪Raytracing来估计优化配置,可以定义为可观察到目标表面上的所有点在传感器上可以看到的占比。如图 2所示的场景覆盖案例,目标O2会被目标O1遮挡,目标O3在Camera可能会被遮挡不可见,但由于雷达路面反射波的原因可能会被Radar检测到,目标O4(交通锥形桶)在视野之内,能否被目标识别模型有效检测到,取决于训练数据是否有小样本问题干扰。短期实现完全通用的多目标检测模型,由于Data Bias原因可能性不大,但可以通过将道路空间数据(图像或者点云)分割成低分辨率Voxel体素,通过Voxel空间占用Occupancy的概率估计,来弥补ADS目标检测中所谓数据长尾效应导致的,对未知障碍物的无法识别导致的避障能力缺失问题。
相对Camera而言,对于3D/4D Radar传感器的能见度估计和逆传感建模,目前研究关注度仍然偏低,多采用Camera数据来配合检测遮挡区域,所以多模态(Camera/LiDAR/Radar)特征提取和时空对齐融合,以及恶劣场景下多模态传感器的选择性融合互补,会大大提升目标识别和空间占用率Occupancy的性能。显然,可靠的自由空间Free-space的信息,运动目标的检测识别跟踪和轨迹行为的预测,尤其是遮挡场景下,对AV安全的轨迹预测和规划来说至关重要。以安全决策为驱动目标的Safety-Assured感知策略,需要通过对能见度状态的有效预测(Occupancy/Free-space/Blind-area),从而避免在不安全的遮挡区或不可行驶(或者叫做不可信)区域进行轨迹规划导致的安全风险。当然也需要避免由于有太多盲区,对遮挡区域的预测认知不足导致功能的可用性减少,从而采用过度保守的规控策略。
场景语义重构Semantic SceneCompletion(SSC)
在ADS的感知应用中,SSC的任务是希望在观察区域内能够联合估计3D场景中目标和路面的几何和语义信息,这显然是非常有挑战的,Camera数据缺乏精确的深度信息,而LiDAR/Radar数据多是稀疏和被遮挡的。两种可行的实现方案如图 1所示,空间离散化或者连续化表征方式。显而易见,通过对传感器数据,包括前视/环视/周视视频,或加上LiDAR/Radar点云数据,进行时空对齐在隐空间融合输出紧凑的3D场景特征连续表达,这可以避免空间离散化方案设计难以解决在不同场景细节级别下语义内容的覆盖难题。如图 4所示,全局的场景重构函数可以通过对多分辨率的局部特征集成或查询来生成不同角度不同分辨率的实时3D场景重建,包括Voxel Occupancy Grid。3D形状和表面语义信息也同样可以隐性表征为输出函数的等值面,与Occupancy及Flow在模型下游进行多任务学习。目前常用的模型架构包括U-Net或Transformer等等,这样可以表达大面积空间内容的同时维持高空间分辨率下预测重构,这包括对数据结构化隐表达进行编码,然后用可学习的深度局部隐函数在不同分辨率下进行解码。输出表征可以通过后处理获得Voxel或者3D Mesh。

图 3场景语义重构SSC的两种实现方案-体素化表征或者连续表征

图 4连续输出函数的在不同分辨率的几何特征表达-LiDAR输入数据案例
产业界引入Occupancy算法的背景
业界在实现自动驾驶的过程中,小样本目标的漏检误检问题,非立体的平面目标画像的误检问题等等,是传统算法无法解决的。其根因可以简单归纳几点:
· 接近地平线的远景区域深度极度不一致问题:
o 小样本目标问题:远距离目标的深度信息消失,或者超低分辨率很难决定一个目标区域的深度(例如图右桥墩漏检后导致致命性车辆撞击问题)
· 遮挡问题:
o 鬼影问题:不能穿透遮挡区域或者行驶车辆来识别被遮挡目标,遮挡目标长记忆轨迹预测困难
· 2D或者2.5D视频约束问题:
o 非立体的平面目标画像问题:难以对应到真实3D场景,难区分静态和动态目标
o 2D目标固定框问题:难以识别悬挂或者悬空的障碍物(可能不在目标检测框内,例如卸货卡车的千斤顶支撑架,卡车货架顶上的人梯等)

Occupancy Network通过添加高度这个维度对2D BEV空间进行扩展,其首先对图像的特征图进行MLP学习生成Value和Key,在BEV空间通过栅格坐标的位置编码来生成Query,新栅格的区别是采用原有的2D栅格和高度一起构成3D栅格,对应生成的特征也从BEV特征变成了Occupancy特征。其设计思路来自机器人设计用的occupancy grid mapping,即将真实3D场景分割成一个个3D的栅格grid。如图 6所示,每个栅格存在两种状态(占用或空闲),可以是多视觉3D呈现的Occupancy Volume,当然为了处理速度,目标的形状不会是一种精确表征,只能是简单逼近,但可以用来区分静态和动态目标(更像是一个3D的blob),可以以3x以上的帧速运行(>100fps),内存占用也非常高效。Occupancy Network将3D空间图分割成一个个超小的cub或者voxel,通过DNN模型做占空两个状态的预测,显然可以解决上述2D目标固定框问题(即所谓的悬空障碍物的问题),以及换了一种思维设计来解决业界难以实现的通用目标检测器的问题(即所谓数据长尾效应下对未知障碍物的识别和避障能力问题)。
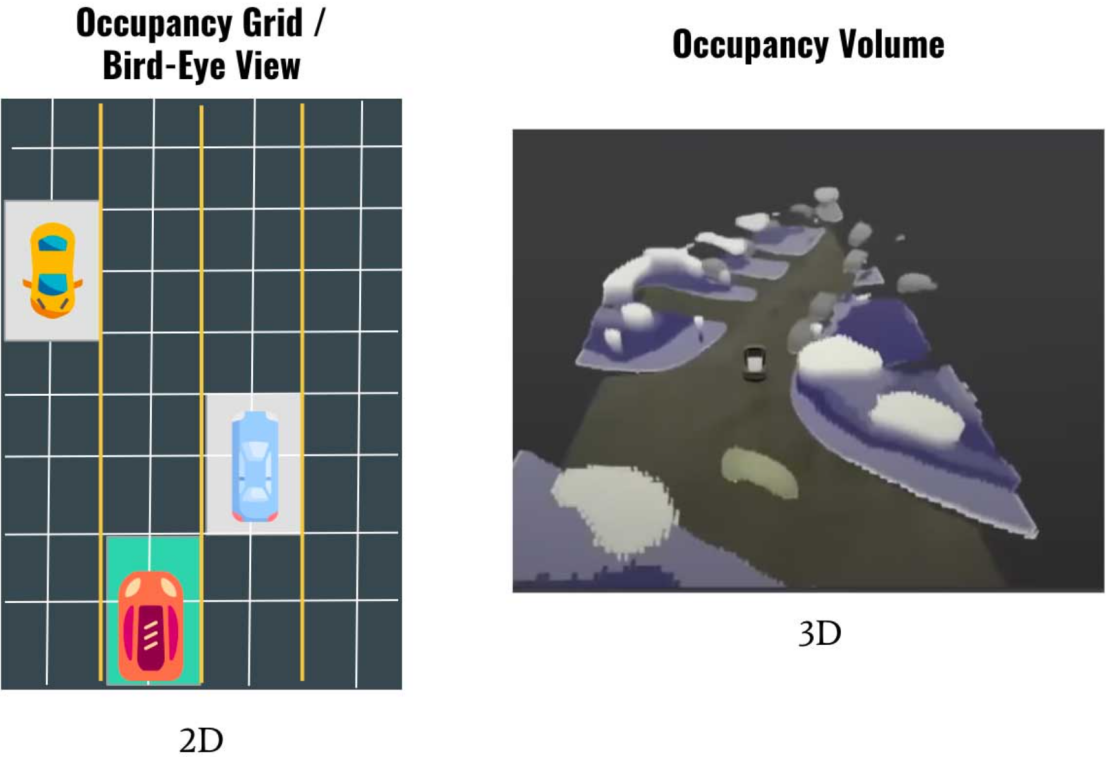
图 6Occupancy Network与HydraNet目标表征对比
复睿微剑桥研究所:聚焦ADS下一代先进算法和架构
复睿微英国剑桥研究中心针对3D Occupancy任务提出了自研的GOP系列模型,可以支持多模态的数据输入,根据图像特征变换和预测采样来建立统一的体素空间,通过使用体素空间编码器对相邻特征进行交互,实现跨模态特征的选择性融合和呈现。
GOP系列模型体素空间Voxel space支持3D空间和多帧场景的空间交互,在体素空间内,多模态数据可以直接进行添加组合,无需复杂的对齐步骤。GOP系列模型支持多尺寸的统一体素空间大小和多任务的输出:可以输出3D目标检测结果,也可以支持输出低精度的3D Occupancy占位信息和高精度的3D语义等众多信息来构建以安全驾驶为核心的、以规控为主导的ADS下一代融合感知能力。
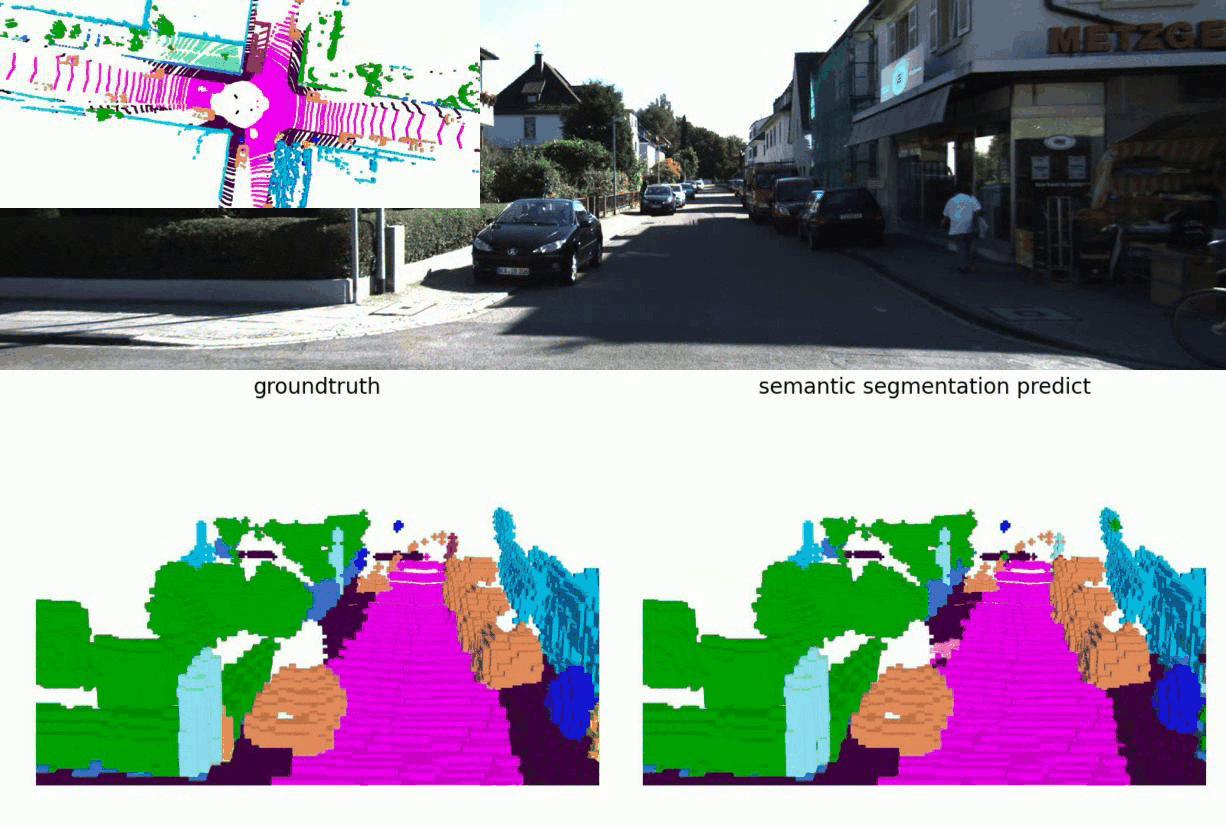

图 7GOP模型Occupancy预测结果展示
上图展示了GOP模型在Semantic Segmentation任务上的效果,在较为拥挤、复杂的道路环境中,能准确稳定地预测出周边场景的3D重建结果。
当前我们的工作还会有众多可以提升的想象空间,复睿微英国剑桥研究所未来会在自动驾驶3D场景感知和重构等方面持续投入,期望在多模态多任务4D时空融合、感知规控联合建模等前沿探索研究领域,能够做出业界领先的原创性技术成果。







