

【嘉勤点评】云天励飞发明的对接TVM方法的专利方案,通过计算图之间的转换,再将转换后的计算图输入到芯片开发环境运行,减少了TVM引入对芯片开发环境的运算资源需求。
集微网消息,TVM(矢量虚拟机)是一个支持图形处理器、中央处理器、现场可编程门阵列指令生成的开源编译器框架,是目前的一项开源项目,主要作用于人工智能深度学习系统的编译器堆栈。
TVM最大的特点是基于图和算符结构来优化指令生成,最大化硬件执行效率。TVM向上可以对接Tensorflow、Pytorch、Caffe等深度学习框架,同时还可以向下可以兼容GPU、CPU、ARM处理器、张量处理器等硬件设备。
当前,TVM无法直接应用在芯片上,但可以将TVM部分功能对接到芯片开发环境中来加速芯片开发流程。TVM使用Relay将深度学习模型构建为计算图,芯片针对计算图中的节点功能进行实现,完成初步硬件部署。
然而,在芯片开发环境引入TVM,会造成运行速率很慢,减缓芯片开发的进度。为此,飞天励云在2020年12月25日申请了一项名为“对接TVM的方法及相关设备”的发明专利(申请号:202011565749.2),申请人为深圳云天励飞技术股份有限公司。
根据该专利目前公开的相关资料,让我们一起来看看这项方案吧。
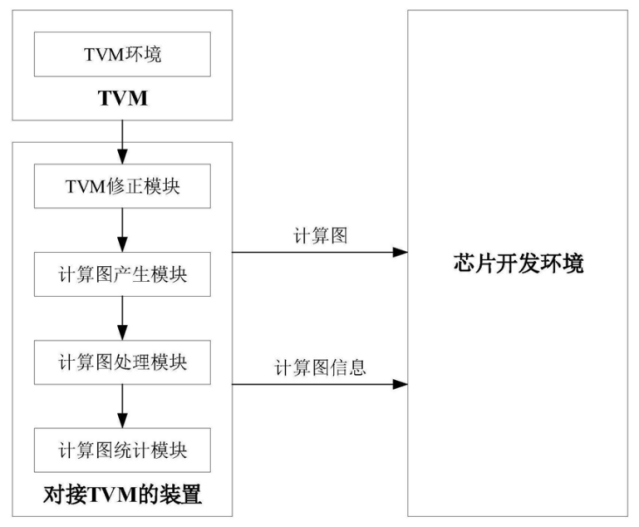
如上图,为该专利中发明的TVM用于芯片开发的系统架构示意图,该系统包括TVM、对接TVM的装置和芯片开发环境,TVM中的TVM环境为历史项目的TVM环境或者原生环境。对接TVM的装置包括:TVM修正模块、计算图产生模块、计算图处理模块以及计算图统计模块。
TVM修正模块用于TVM根据目标模型生成第一计算图,目标模型可用于芯片的开发;计算图产生模块可以根据第一计算图生成第二计算图,第二计算图是芯片开发所使用的计算图结构,之后,会将第二计算图输入到芯片开发环境中运行。
为何要进行计算图的转换呢?这是由于TVM是一个很大的环境,如果将TVM根据生成的第一计算图输入芯片开发环境中运行,例如直接将TVM Relay计算图输入芯片开发环境中运行,会造成运行速率很慢,减缓芯片开发的进度。
造成运行速率缓慢的原因是:因为第一计算图的结构大,且不是芯片开发所使用的计算图结构,因此其运行所需的运算资源需求较大。而如果将第一计算图经过结构转换,将其转换成芯片开发使用的计算图结构的第二计算图,再将第二计算图输入到芯片开发环境中运行,可以明显减少运行所需的运算资源需求,从而提升运行速率。
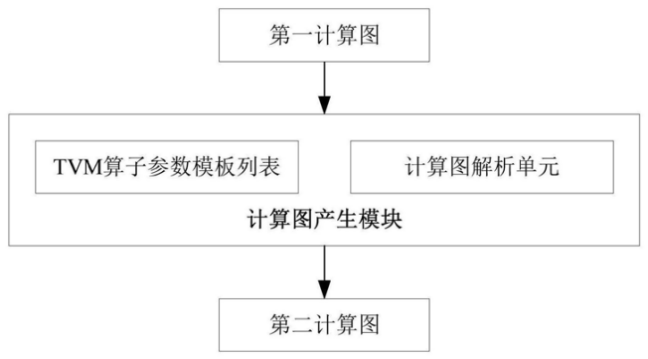
如上图,为该专利中发明的计算图产生模块的结构示意图,该计算图产生模块的输入为TVM Relay计算图,输出为根据芯片开发需要的算子信息组成的芯片开发使用的计算图结构,也就是上述提到的第二计算图。
新产生的计算图中包括有TVM算子参数模板列表和计算图解析单元,可以根据模板列表解析出TVM Relay计算图中的节点对应的算子名称、算子参数、输入和输出数据的维度以及节点标号等。
以上就是云天励飞发明的对接TVM方法的专利方案,该方案将第一计算图转变第二计算图,再将第二计算图输入到芯片开发环境运行,能够极大减少TVM引入对芯片开发环境的运算资源需求,不仅提升了运行速率,也可以减少芯片开发环境的运行时间。
关于嘉勤

深圳市嘉勤知识产权代理有限公司由曾在华为等世界500强企业工作多年的知识产权专家、律师、专利代理人组成,熟悉中欧美知识产权法律理论和实务,在全球知识产权申请、布局、诉讼、许可谈判、交易、运营、标准专利协同创造、专利池建设、展会知识产权、跨境电商知识产权、知识产权海关保护等方面拥有丰富的经验。
(校对/holly)


